


Flink中的时间语义
事件时间和处理时间
为什么要研究Flink中的时间意义?
对于一个流式系统,要求数据处理实时性,尤其是Flinkh中的keyBy操作,如果要求对时间做分类,例如处理8~9点的数据,就可能产生如下场景:
一条数据生成是8:59:59,到达Flink节点1的时间是9:00:01,那么这条数据应该算作8~9点的数据吗
其中涉及了两个概念:
事件时间:每个事件在对应的设备上发生的时间,也就是数据生成的时间。数据一旦产生,这个时间自然就确定了,所以它可以作为一个属性嵌入到数据中。这其实就是这条数据记录的“时间戳”(Timestamp)
处理时间:指执行处理操作的机器的系统时间
大部分场景下,事件时间做为默认的时间标定更符合主观思维,因为处理时间可能还会受到一些网络、积压等问题的影响
而Flink确实也是将事件时间做为了默认的时间语义,即节点处理数据时根据数据上的时间戳来判定当前处于什么时间范围,假设系统时间是9:01,节点还在处理8:59的数据,节点也会认为目前的时间是不到9点的,即还可能有8点数据到来,除非有一条9点的数据进入
水位线
水位线的特征
假设有一个场景:
节点A、B、C执行8~9点的数据收集任务,收集完成后开始进行计算,当一个9:01数据生成并发给了节点B,节点B知道目前时间已经到达了9点,开始进行计算了,如果A、C一直没收到新数据,那么A、C就会持续等待
为了规避这种情况,上游会定期发送一条特殊数据,只携带时间戳,用于推进Flink系统中的时钟,这条特殊数据就叫水位线Watermark
这里的定期指的是系统时间,因此水位线还是会有一点点的时间偏差,不可避免
在顺序和乱序事件中,水位线的特性不同:
如果流式系统中事件一定是保证顺序的,那么节点每次接收到水位线就会更新自己的时钟
如果系统中的数据是时间乱序的,还是按照水位线则有三种生成思路:
周期性收集一批数据的时间戳,选择其中最大的生成水位线,用于推进系统时钟
拿到生成水位线的时间戳后,与上一个水位线进行对比,如果比上一条还小,就不生成新的水位线,避免时钟回退
拿到生成水位线的时间戳后,生成的水位线时间回退x分钟,用于对一些延迟数据进行宽容
总结起来,水位线的特性包括:
是一条特殊数据,用于推进系统时钟
生成周期基于系统时间,但携带的时间戳取自于事件时间
必须单调递增,不能时光倒流
生成水位线的方法
DataStream#assignTimestampsAndWatermarks 方法
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(WatermarkStrategy<T> watermarkStrategy) {
WatermarkStrategy<T> cleanedStrategy = (WatermarkStrategy)this.clean(watermarkStrategy);
int inputParallelism = this.getTransformation().getParallelism();
TimestampsAndWatermarksTransformation<T> transformation = new TimestampsAndWatermarksTransformation("Timestamps/Watermarks",
inputParallelism, this.getTransformation(), cleanedStrategy, false);
this.getExecutionEnvironment().addOperator(transformation);
return new SingleOutputStreamOperator(this.getExecutionEnvironment(), transformation);
}该方法传入了一个WatermarkStrategy
public interface WatermarkStrategy<T> extends TimestampAssignerSupplier<T>, WatermarkGeneratorSupplier<T> {
WatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context var1);
default TimestampAssigner<T> createTimestampAssigner(TimestampAssignerSupplier.Context context) {
return new RecordTimestampAssigner();
}
……水位线策略中包括两个能力:
WatermarkGenerator:水位线生成器,按照既定的方式,基于时间戳生成水位线,有两种方法:
onEvent:每个消息过来实时调用
onPeriodicEmit:周期调用
TimestampAssigner:时间戳提取器,主要负责从流中数据元素的某个字段中提取时间戳,并分配给元素。时间戳的分配是生成水位线的基础。
Flink中提供的内置水位线生成器包括:
适合有序流的单调递增生成器:
WatermarkStrategy#forMonotonousTimestamps生成的AscendingTimestampsWatermarks适合乱序流的延迟生成器:
WatermarkStrategy#forBoundedOutOfOrderness生成的BoundedOutOfOrdernessWatermarks,传入一个延迟就可以生成带延迟的水位线
也可以自行实现WatermarkStrategy自定义水位线策略
也可以在自定义的SourceFunction数据源中自行发送水位线,就无需使用assignTimestampsAndWatermarks添加水位线策略了
public static class ClickSourceWithWatermark implements SourceFunction<Event> {
private boolean running = true;
@Override
public void run(SourceContext<Event> sourceContext) throws Exception {
Random random = new Random();
……
Event event = new Event(username, url, currTs);
// 使用 collectWithTimestamp 方法将数据发送出去,并指明数据中的时间戳的字段
sourceContext.collectWithTimestamp(event, event.timestamp);
// 发送水位线
sourceContext.emitWatermark(new Watermark(event.timestamp - 1L));
Thread.sleep(1000L);
}
}
@Override
public void cancel() {
running = false;
}
}
// 添加对应的数据源
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSourceWithWatermark()).print();
env.execute();使用addSource添加自定义水位线时,就不能再使用assignTimestampsAndWatermarks 添加内置水位线了
在数据流开始之前,Flink会插入一个大小是负无穷大(在Java中是-Long.MAX_VALUE)的水位线,而在数据流结束时,Flink会插入一个正无穷大(Long.MAX_VALUE)的水位线,保证所有的窗口闭合以及所有的定时器都被触发
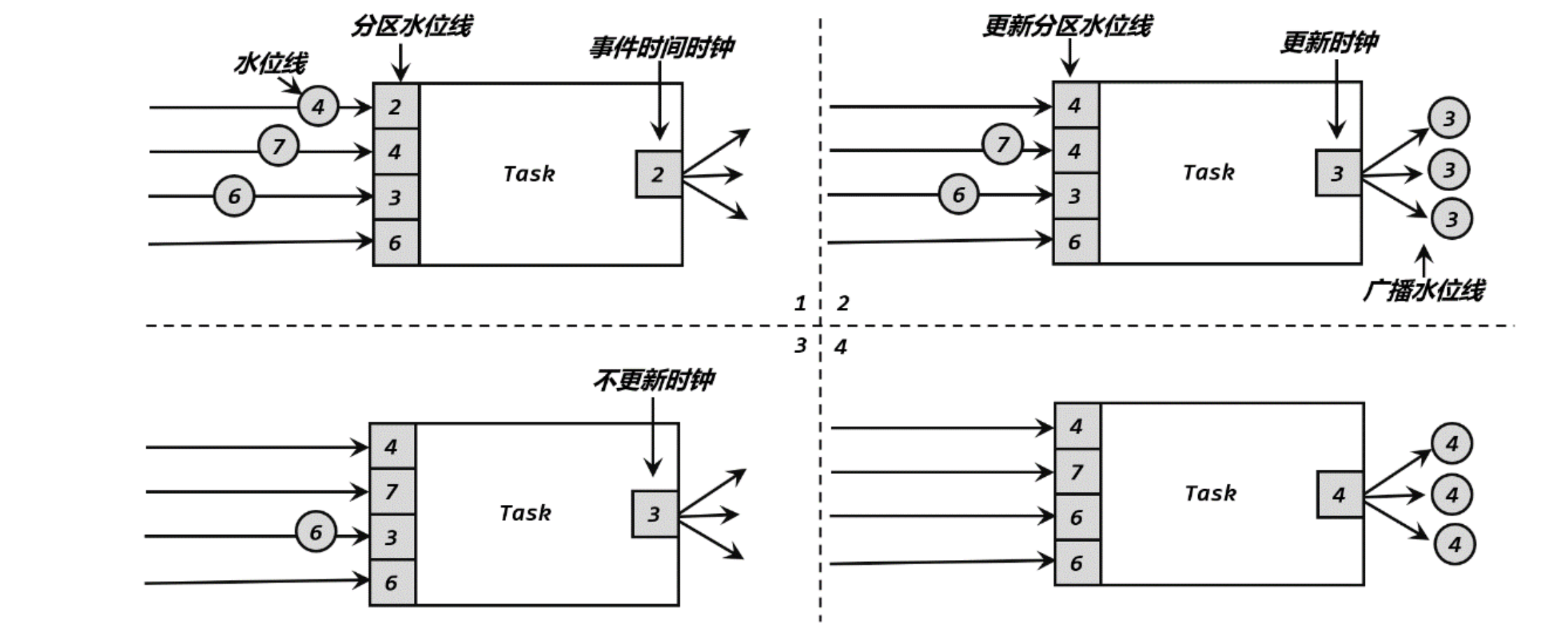
水位线传递策略
如果一个算子上游是多个算子流合并,这个算子会存储分区水位线PartitionWatermark,一个周期内的数据中,PartitionWartermark按上面的水位线策略生成
最终的水位线取各个分区水位线中的最小值,如果最小值还小于当前的水位线,则不刷新
Flink中的时间窗口
时间窗口的概念
与其说时间窗口,倒不如说是时间桶
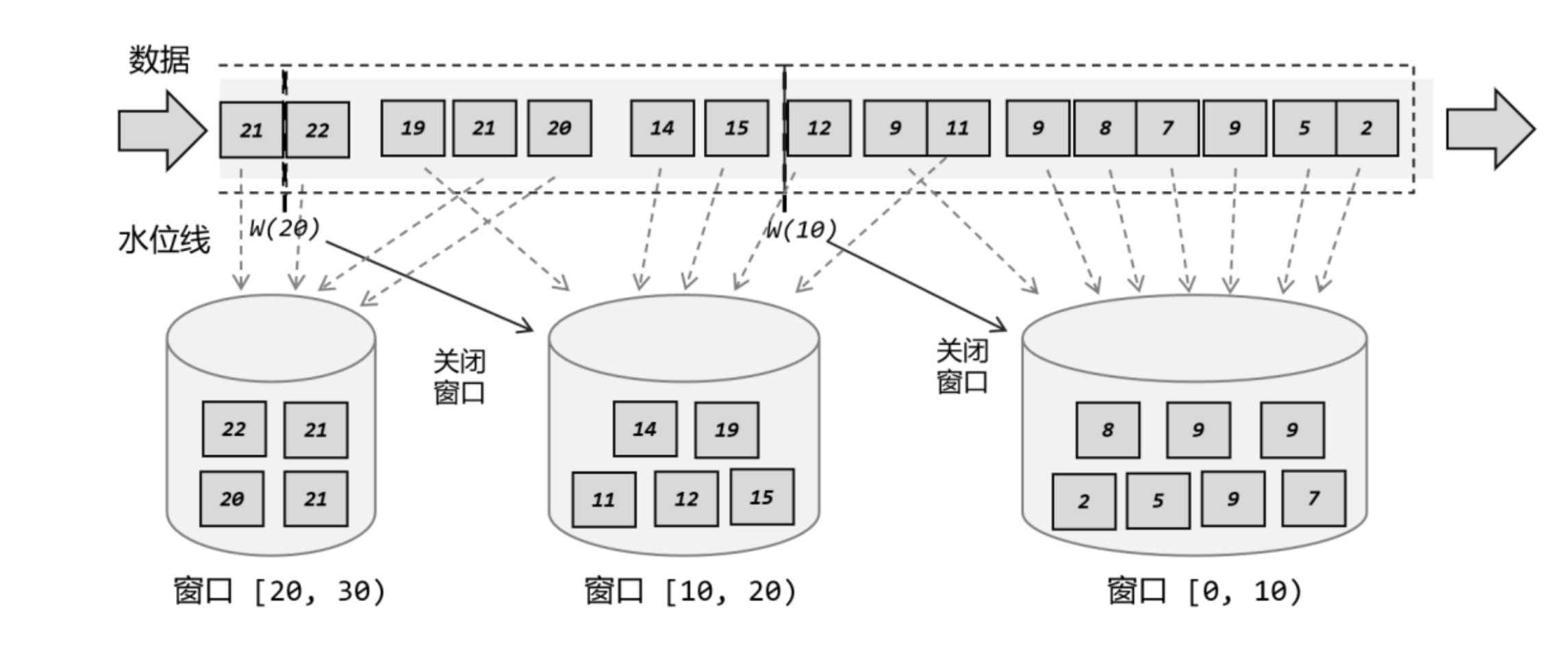
假设一个场景:每过10s收集所有数据,一起处理,使用的水位线是-2的延迟策略
假设目前系统时钟推进到了第20s,即实际已经有22s的数据产生了,这时数据应该要被分类进两个桶里:11~20s、21~30s
但实际只有这两个桶吗?并不是,还有0~10s的桶,只是已经被关闭了,因为当前系统时钟都已经推进到第20s了,默认不会有延迟数据出现了,就算出现也不处理了
然后时钟推进到21s时,11~20s的桶也将被关闭
这里需要注意的是,Flink中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗口
时间窗口分类
按驱动进行分类包括:
时间窗口:最常见的一种类型,即上面的案例,每个几秒生成一个窗口,归档对应时间戳的数据
计数窗口:也是一种常用类型,例如人满发车这种场景
按窗口分配数据规则包括:
滚动窗口(Tumbling Windows):滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。因此看起来就像是在滚动一样。因此生成一个滚动窗口的唯一条件就是窗口大小。它常用于一些BI指标分析场景
滑动窗口(Sliding Windows):与滚动窗口的区别是,前后两个窗口可以交错,也可以有间隔。在这种场景下一条数据可能被分配到多个窗口中。构建滑动窗口则需要两个条件:窗口大小和步长。假设窗口大小是30min,步长是15min,窗口A是00:00~00:30,窗口B是00:15~00:45,则00:20的数据则被分配到两个窗口了。这种窗口适合实时监控、高频监控一个时间段内的数据波动,例如股票大盘
会话窗口(Session Windows):数据来了之后就开启一个会话窗口,如果接下来还有数据陆续到来,那么就一直保持会话;如果一段时间一直没收到数据,那就认为会话超时失效,窗口自动关闭。会话窗口只能基于时间来定义,没有会话计数窗口的概念。
全局窗口(Global Windows):还有一类比较通用的窗口,就是“全局窗口”。这种窗口全局有效,会把相同key的所有数据都分配到同一个窗口中;说直白一点,就跟没分窗口一样。无界流的数据永无止尽,所以这种窗口也没有结束的时候,默认是不会做触发计算的。如果希望它能对数据进行计算处理,还需要自定义“触发器”(Trigger)。
评论区