


参数量
参数量是大模型的一个关键指标,决定了模型的复杂度、表现力和计算需求。简单来说,参数量就像是模型的大脑,它包含了模型在训练过程中学习到的所有信息
参数量与如下方面产生影响:
学习能力:参数量越大,模型更能够捕捉更复杂的数据模式,例如GPT-4约1.8万亿个参数(1800b),就会有更好的文本生成能力
计算成本:参数量越大,模型的计算需求增加,则需要更多的计算资源和训练时间
存储需求:参数量越大,模型需要的存储空间越多,硬件配置就更高
泛化能力:参数量越大,越容易过拟合,因此需要平衡参数量
Token
在大模型中,Token代表模型理解和处理文本的最小单位。每个Token都可以是一个单词、字符或符号,甚至是一个短语
Token概念的意义:
过程Token化:文本被分解为Token,开源预测模型执行任务的成本
语义Token化:将文本划分为Token,开源以更小的单位处理词组,对每个词组使用更细致的策略
上下文
上下文就是一次对话所处的语言环境
上下文窗口是指在生成文本时,模型能一次性“看到”的最大文本长度。这个窗口决定了模型在生成每个Token时,参考多少前文信息
上下文长度是指模型一次性能够处理的最大Token数量,决定了模型能够处理多长的输入
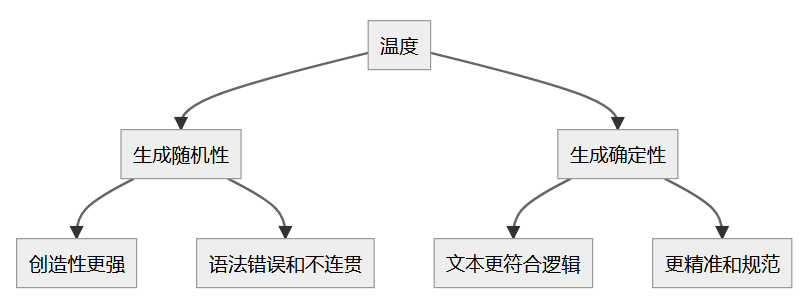
温度
温度用于调节模型生成文本时随机性与确定性的参数。通过调整温度,我们可以控制模型生成内容的创造性与准确性之间的平衡
低温度时(0.2):输出内容更规范,符合逻辑,适用于高精度任务
高温度时(0.8):输出内容更具创造性,但可能包含不规范或不连贯的元素,适用于需要创新的任务,如写作或创意生成
指令、蒸馏、量化
分类
大模型随着能力的特性化,分为基础模型、指令模型、蒸馏模型、量化模型
基础模型:是一个拥有巨大数据集的模型
指令模型:经过指令训练的微调模型,例如提供了很多“问题-正确答案”的例子,模型学会了如何根据用户提出的问题做合理的解答,例如解答模板是5W1H,训练多了,模型就会固化这种答题思路
蒸馏模型:将基础模型比作一个会所有语言的高级程序员,蒸馏模型就是在工作中只选择特定领域只是进行保留的模型,例如将高级程序员的工作思路喂给小模型,训练一个专门处理JAVA代码的小模型
量化模型:降低模型精度,换取性能的模型。量化精度场景有FP32(32位浮点数)、FP16/BP16(16位浮点数)、INT8(8位整数)、INT4(4位整数),可以类比为原画、高清、高清压缩版、标清。例如模型数据集中圆周率有32位,而量化压缩到INT4则只记整数3就行了
模型蒸馏的思路
可以想象一下,老师教学生,就是将老师的思路灌输给学生,让学生学会答题
数据集准备
首先准备包含instruction的数据集,例如:
[
{
"instruction": "中国的首都是哪里?"
},
{
"instruction": "请用一句话解释什么是人工智能。"
},
{
"instruction": "帮我写一封邮件,邀请同事参加周五的项目总结会。"
}
]可以对数据集做增强,例如以下方法:
指令增广:让一个模型根据现有指令,仿写更多语义相近但表述不同的新指令
指令优化:将简短模糊的指令写得更加详细、清晰,以激发模型的高质量回复。例如“如何做鱼香肉丝?”可以优化为“请提供一个详细的中国四川风味的鱼香肉丝的食谱,包括具体材料清单和详细的步骤说明”
利用大模型生成标准答案
利用老师(大模型),将指令喂给老师,从而生成答案,这些答案叫软标签/指令-蒸馏数据集
在利用大模型生成软标签的时候,有两个参数比较重要:
temperature:控制生成文本的随机性,默认0.8,可以根据自己希望小模型未来的工作模式,可以调高或调低
max_new_tokens:控制生成答案的最大长度,确保它大于预期标准答案的最大值,如果太短,标准答案就会被截断。对于需要推理的任务,可以适当大一点
在生成标准答案的时候,还可以将大模型(如果是推理模型的化)的推理链路进行扩写或缩写处理,生成带有详细推理步骤的数据,能有效增强小模型的推理能力
训练学生模型
用上一步的蒸馏数据集训练小模型,本质上是一个监督微调(SFT)的过程
在训练时,也有几个核心参数:
learning_rate:学习率,控制模型参数更新的步长,默认5e-5是一个不错的起点,如果损失下降缓慢可以适当调大,损失震荡则可以调小
num_train_epochs:训练轮次,根据训练集大小和损失调整,通常3-10轮
per_device_train_batch_size:单次训练批次大小,越大越快,吃GPU
例如下面这个将Qwen3-235B模型数据集训练为0.6B的模型,在特定任务上的准确率有98%
swift sft \
--model Qwen/Qwen3-0.6B \ # 指定学生模型
--train_type lora \ # 使用LoRA微调
--dataset 'train.jsonl' \ # 上一步生成的蒸馏数据
--num_train_epochs 10 \ # 训练10个epoch
--per_device_train_batch_size 20 \
--learning_rate 1e-4一些训练的思路包括:
损失函数设计:在训练时,通常会组合两种损失函数来指导学生模型:
KL散度损失:衡量学生模型的输出概率分布与教师模型的“软标签”之间的差异,让学生学会教师的“判断逻辑”。
任务损失:即传统的交叉熵损失,让学生模型不要偏离真实的标准答案(如果有的话)。
先剪枝再蒸馏:NVIDIA的实践表明,可以先对学生模型进行结构化剪枝(如减少层数或注意力头数),然后再进行蒸馏,可以获得更好的效率和性能平衡。
先蒸馏后量化:蒸馏和量化是“好朋友”。你可以先通过蒸馏得到一个较小但性能强的模型,然后再用我们上次讨论的量化技术(如INT4、INT8)对它进行二次压缩,实现极致的推理加速。
模型微调的思路
跟蒸馏差不多,模型微调也是通过数据集对模型进行训练
一般模型微调的思路包括:
全量微调:全量调整所有的参数,消耗极大,谁也不想这么搞
部分微调:性能和成本都很低了,甚至可以在个人PC上微调大模型
部分微调思路包括:
LoRA - 低秩适配:相当于保持原始大模型的原始参数不动,给他外挂一些小的补丁,它的技术原理是:
冻结大模型的原始参数,不参与计算
在模型的关键层插入小的矩阵A、B,这两矩阵的参数量极其少
训练时只有这些小矩阵A和B的参数更新,训练后得到几个小文件
训练后,要么把这几个小补丁回合到大模型,要么利用这些独立文件每次动态加载
QLoRA - 量化低秩适配:LoRA的超级省钱版,将大模型量化压缩,然后再做LoRA给他训练补丁,思路是:
先把原始大模型进行4-bit量化,然后冻结
在压缩后的量化模型上插入LoRA小矩阵,保持原始的16-bit精度
计算梯度要更新小矩阵数据集的时候,把4-bit的压缩数据临时解压缩为16-bit,计算完再解压回去
LoRA的优势在于精度高,速度快,QLoRA的优势在于成本低消费显卡也可以做,但是略慢,且有精度损失
一个本地做模型微调的案例:
准备环境
# 安装必要的库
# !pip install transformers datasets peft accelerate bitsandbytes trl
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
from trl import SFTTrainer
from datasets import load_dataset
import torch准备数据
例如一个客服问答数据集,质量和数量之间更追求质量,效果更好
# 准备一个简单的客服问答数据集
dataset = load_dataset("json", data_files="customer_service.json")
# 数据格式示例 (customer_service.json):
# [
# {
# "instruction": "用户问:订单还没发货怎么办?",
# "output": "您好,一般订单会在24小时内发货。请您提供订单号,我帮您查询具体状态。"
# },
# ...
# ]
# 定义一个格式化函数,将数据转换成模型训练需要的对话模板
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['instruction'])):
text = f"### 用户: {example['instruction'][i]}\n### 客服: {example['output'][i]}"
output_texts.append(text)
return output_texts加载模型配置LoRA
使用QLoRA,加载量化的4-bit模型
# 1. 配置 QLoRA 的4-bit量化参数,这是省显存的关键
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 加载4bit量化模型
bnb_4bit_quant_type="nf4", # 使用NF4量化类型,效果更好
bnb_4bit_compute_dtype=torch.float16, # 计算时用float16
bnb_4bit_use_double_quant=True, # 启用双重量化,进一步省显存
)
model_name = "meta-llama/Meta-Llama-3-8B-Instruct"
# 2. 加载4bit量化的基础模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config, # 应用上面的量化配置
device_map="auto", # 自动分配到GPU
trust_remote_code=True
)
# 3. 配置 LoRA 参数
peft_config = LoraConfig(
r=64, # LoRA秩,越大代表可学习的参数越多,效果可能越好,但并非越大越好
lora_alpha=16, # 缩放参数
lora_dropout=0.1, # 防止过拟合
target_modules=["q_proj", "v_proj"], # 在注意力层的Q、V矩阵上应用LoRA
bias="none",
task_type="CAUSAL_LM"
)
# 4. 将LoRA适配器附加到模型上
model = get_peft_model(model, peft_config)
# 查看可训练的参数数量,通常只占模型总量的极小一部分
model.print_trainable_parameters() 开始训练
启动训练,训练完成后得到的是一个LoRA外挂文件
# 设置训练参数
training_args = TrainingArguments(
output_dir="./llama3-customer-finetuned-lora", # 模型保存路径
per_device_train_batch_size=4, # 根据显存调整,QLoRA下可以设为4或8
gradient_accumulation_steps=4, # 梯度累积,模拟更大的batch size
learning_rate=2e-4, # LoRA的学习率通常比全量微调大
num_train_epochs=3, # 训练3轮,小数据集可以多几轮
logging_steps=10, # 每10步打印一次日志
save_strategy="epoch", # 每轮结束后保存一次模型
fp16=True, # 启用混合精度训练,加速
warmup_ratio=0.1, # 学习率预热比例
)
# 创建Trainer并开始训练
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
formatting_func=formatting_prompts_func,
max_seq_length=512, # 最大序列长度
tokenizer=tokenizer,
)
trainer.train() # 开始训练
# 训练完成后,保存最终的LoRA适配器权重
model.save_pretrained("./llama3-customer-service-lora-adapter")确认效果
训练结束后,我们可以加载保存的 LoRA 权重,来测试一下微调后的模型
# 推理测试
from transformers import pipeline
# 加载微调后的模型
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
prompt = "### 用户: 我的退款申请还没处理,怎么办?\n### 客服:"
result = pipe(prompt, max_new_tokens=100, do_sample=True, temperature=0.7)
print(result[0]['generated_text'])RAG
RAG:Retrieval-Augmented Generation,即检索增强生成。它就是给大模型开卷考试的权利
传统的大模型就像是闭卷考试,知识已经全部学习过了,只能凭借记忆回答,缺点就是如果记错了(模型幻觉),或者考了新知识(学习之后发生的事情),大模型就不会
RAG的作用就是给了大模型一本参考书,考试时先去书里找相关章节,然后结合自己的理解生成答案
RAG的流程是用户提问->检索->增强->生成
RAG与微调不同,微调发生在代码层面,而RAG发生在交互层面,是通过一些API接口喂给大模型的,组建的RAG就是通过组装提示词完成的,例如:
【系统指令】你是一个专业的客服助手。请基于以下资料,回答用户的问题。
如果资料中没有相关信息,请诚实地说明不知道,不要编造。
【参考资料】
1. 退货政策:自签收之日起7天内,可申请无理由退货...
2. 退货流程:请登录APP,在订单页面申请退货...
3. 退货注意事项:商品需保持完好,配件齐全...
【用户问题】
你们的退货政策是什么?
【请回答】而调用大模型api例如:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一个客服助手,请基于参考资料回答..."},
{"role": "user", "content": "退货政策:自签收之日起7天内...\n\n问题:你们的退货政策是什么?"}
]
)
评论区