


VSCode
格式化:ctrl + alt + F
上移/下移一行:光标所在位置,alt + up / alt + down
快速复制一行代码:光标所在位置,shift + alt + up / shift + alt + down
快速保存:ctrl + s
快速查找:ctrl + F
快速替换:ctrl + H
快速生成html六级标题:h$*6
快速生成六个表项的无序列表:ul>li*6
快速生成3*3表格:table>tr*3>td{单元格}*3
快速生成html代码:在html文件后缀下输入!
IDEA
常用设置
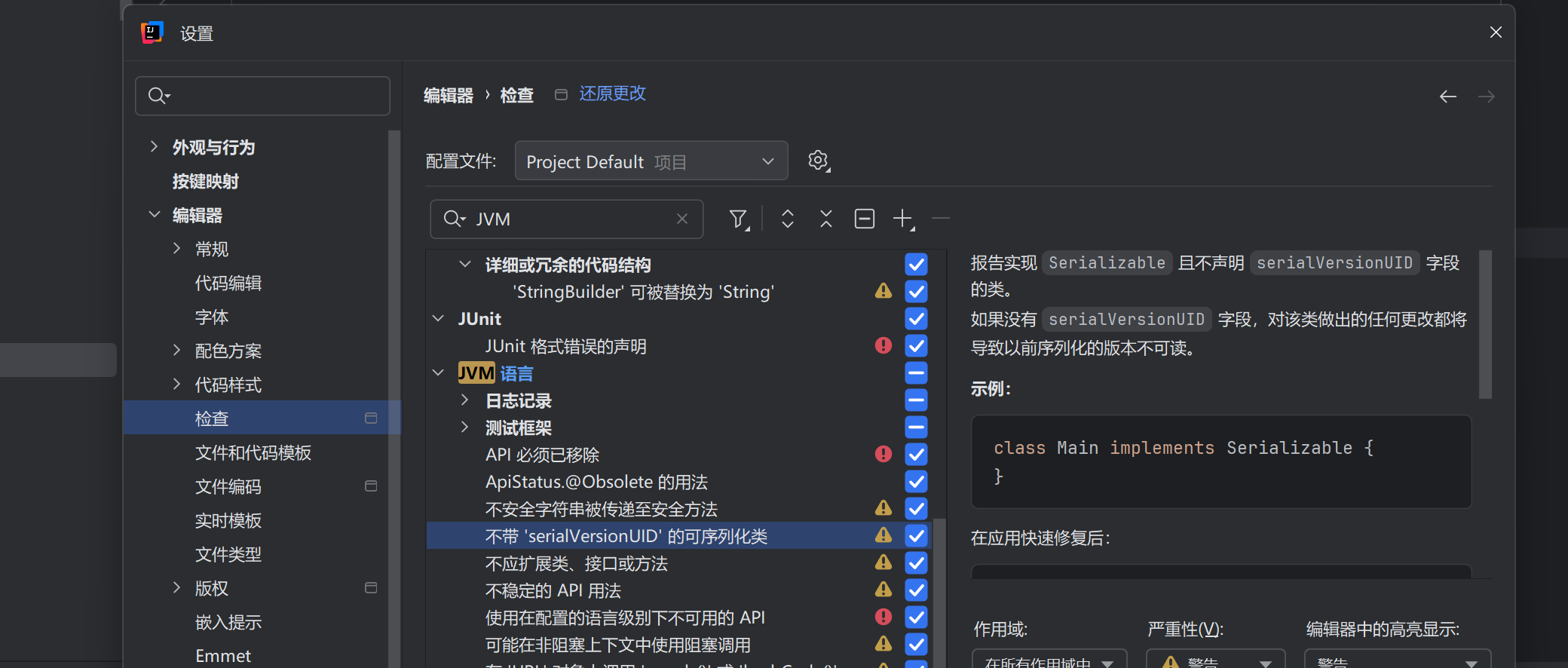
设置默认实现Serializable接口的类自动添加随机的serialVersionUID
使用profile工具分析内存
使用IntelliJ profile分析xxx可以直接执行
也可以安装Eclipse出的Memory Analysis Tool分析hprof文件
ctrl + shift + j:格式化的json转1行
ctrl + alt + h:查找方法调用链路
ctrl + h:查找class的类结构
编译与反编译java
public class ByteCodeTest {
private int m;
public int inc() {
return m+1;
}
}以这个类为例,在类上点击打开于-终端,执行javac ByteCodeTest.java 然后再执行 javap -verbose .\ByteCodeTest.class ,可以看到字节码如下:
public class com.huawei.cbc.udrmetricservice.jvmtest.ByteCodeTest
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #4.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #3.#16 // com/huawei/cbc/udrmetricservice/jvmtest/ByteCodeTest.m:I
#3 = Class #17 // com/huawei/cbc/udrmetricservice/jvmtest/ByteCodeTest
#4 = Class #18 // java/lang/Object
#5 = Utf8 m
#6 = Utf8 I
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 inc
#12 = Utf8 ()I
#13 = Utf8 SourceFile
#14 = Utf8 ByteCodeTest.java
#15 = NameAndType #7:#8 // "<init>":()V
#16 = NameAndType #5:#6 // m:I
#17 = Utf8 com/huawei/cbc/udrmetricservice/jvmtest/ByteCodeTest
#18 = Utf8 java/lang/Object
{
public com.huawei.cbc.udrmetricservice.jvmtest.ByteCodeTest();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
public int inc();
descriptor: ()I
flags: ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: aload_0
1: getfield #2 // Field m:I
4: iconst_1
5: iadd
6: ireturn
LineNumberTable:
line 8: 0
}
SourceFile: "ByteCodeTest.java"BeyondCompare
在右边的内容处点F7,可然后选定左边的某一行,可以设置强制将两边进行对齐
Kibana
text与keyword
在Kibana中,使用.keyword后缀是为了访问字段的keyword类型子字段。这是因为在Elasticsearch中,一个字符串字段可能被映射为两种类型:text和keyword。默认情况下,如果索引一个字符串字段,Elasticsearch会自动将其映射为text类型,并创建一个名为keyword的子字段,类型为keyword。
text类型:会进行分词处理,适用于全文搜索。在Kibana中,如果你对text类型字段进行搜索,你会使用分词后的词条进行匹配,并且可以使用各种文本搜索功能(如通配符、正则表达式等),但注意,text类型的分词器可能会将单词拆分开,所以你不能用text字段进行精确匹配(除非使用match_phrase等)。keyword类型:不会分词,将整个字符串作为一个词条存储,适用于精确匹配、排序、聚合。在Kibana中,如果你想要对某个字符串字段进行精确匹配(比如等于某个值)或者进行聚合操作,那么你需要使用.keyword后缀来指定该字段的keyword类型。
例如,有一个关键词:response,日志如下:Error: connection timeout
response: timeout-> 可以匹配,因为text类型分词后包含“timeout”response.keyword: timeout-> 不能匹配,因为整个字符串不是“timeout”response: *timeout*和response.keyword: *timeout*可匹配,这两个可以都试试
VimiumC
暂停和启用:i暂停,ecs启用
评论区