


linux的namespace、cgroup机制
linux的namespace、cgroup机制是docker实现的原理,参考linux部分
docker架构概览
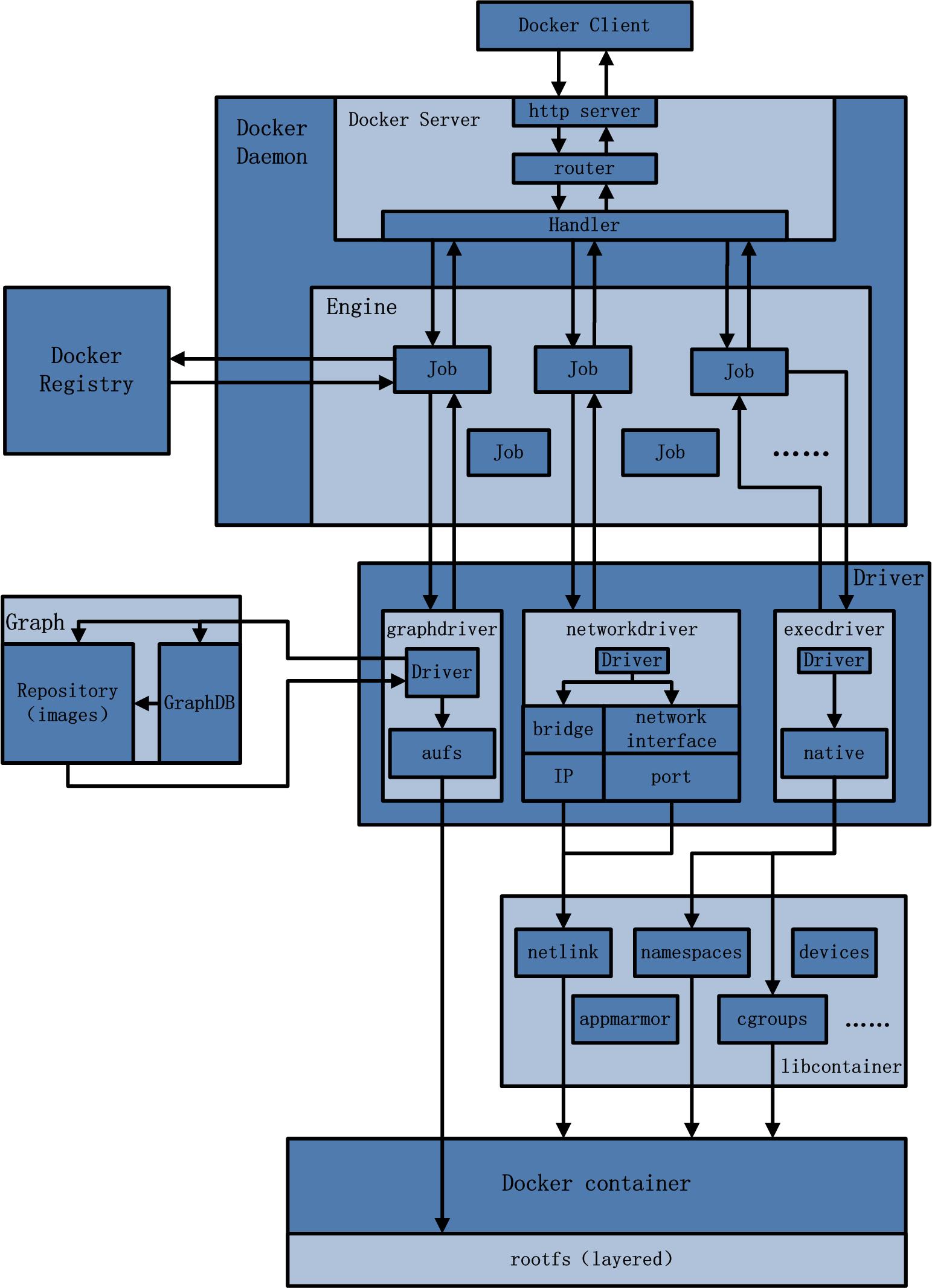
比较核心的有docker daemon、client、volume等
docker daemon
docker daemon是专门负责响应docker client的请求的(通过socket连接),它就是本地启动的服务端API Server,接收client的请求,分发调用具体函数。daemon进程也是docker的守护进程。
docker client
docker client就是用户使用docker的客户端,它是一个概称,只要是遵循了docker API的客户端都可以叫docker client,例如支持windows的C#版、命令行的linux版、JAVA版等
镜像管理
包括distribution、registry、layer、image、reference等,这些模块统称镜像管理(image management)。功能如下:
distribution:负责与docker registry交互,上传下载镜像,存储
registry:负责身份验证、镜像查找、镜像验证、管理registry mirror
image:负责镜像元数据有关的存储、查找,tar包导入导出等操作
reference:存储本地所有镜像的repository和tag名,维护镜像ID之间的映射关系
layer:负责镜像层与容器层元数据的增删改查,将镜像层的增删改查操作映射给graphdriver模块,进行容器层增删改查
execdriver、volumedriver、grapdriver
execdriver:容器执行驱动,对linux底层的namespace、cgroups、apparmor、SELinux等功能进行二次封装
volumedriver:是volume数据卷存储操作的最终执行者,负责volume增删改查、屏蔽
graphdriver:所有与容器镜像相关的最终执行者,维护容器层与镜像层的对应关系
network
docker网络基于libnetwork库实现,抽象了一个容器网络模型(Container Network Model,CNM),并给调用者提供了一个统一抽象接口。CNM模型抽象出了沙盒(sandbox)+端点(endpoint)+网络(network)3个对象
client和daemon
client模式和daemon模式
一条docker命令的构成是:
docker <options> command <arg….>其中的options称为flag,执行docker命令要先解析这些falg,判断command指向的子命令对应的操作模式
docker命令有client模式和daemon模式
如果子命令为daemon,docker就会创建一个运行在宿主机上的daemon进程执行daemon模式,其余子命令都执行client模式
client模式的工作流程
client模式docker命令有以下工作流程:
解析flag信息:例如
Debug(-d和--debug)、LogLevel(对应-l和--log-level)、Hosts(对应-H和--host=<>)创建client实例:在已有参数配置基础上创建client实例
执行具体命令:交给
cli/cli.go执行,在这个过程会给docker daemon发POST、GET请求,读取来自docker daemon的返回结果
daemon模式工作流程
docker要启动并初始化一个server(即docker daemon)负责处理接收到的请求,过程如下:
API Server的初始化
按照用户配置完成server的初始化,并启动,例如参数解析、创建PID、网络配置、路由表、channel、信号等。
如果处理完成,启动的docker daemon会向宿主机init进程发送一个READY=1的信号,否则调用shutdownDaemon关闭。
daemon对象的创建与初始化
完成docker容器配置信息、工作路径配置、用户权限、加载grapdriver、创建docker网络等。docker启动的工作路径结果包括:
/var/lib/docker
|----aufs # aufs驱动工作目录
|----|----diff # aufs文件系统所有层存储目录,包括新下载的镜像内容
|----|----layers # aufs层直接的关系等元数据
|----|----mnt # aufs文件系统挂载点
|----containers # 容器主配置文件目录,例如xx-json.log、conf.json、hostconfig.json、hosts等
|----image/aufs # 存储镜像和镜像层信息,只是元数据,真正镜像层内容在aufs/diff下
|----|----imagedb # 所有镜像的元数据
|----|----layerdb # 镜像层和容器层的元数据
|----|----repositories.json # 记录repositroy和tag名
|----|----distribution
|----volumes # volumes工作目录,存放所有volume数据和元数据还要创建docker网络,包括host、null、bridge、overlay的驱动
然后初始化execdriver,最终生成daemon对象。同时在docker daemon启动时会查看daemon.repository恢复已有的docker容器
命令从client到daemon
以docker run为例,分析从client到daemon之间命令交互的流程:
发起请求
用户使用cli提交了docker run命令,这里新建了一个client,通过反射找到CmdRun方法,并且执行并向daemon发起了一个POST请求,调用containerValues创建容器。
创建容器
docker daemon解析POST请求,使用对应参数新建了一个container对象(注意这里是libcontainer里面的存储配置信息的对象,小写c开头,不是真正的容器),但是这里还不启动,只是有容器对象,然后将其信息作为response返回给client,然后client紧接着发送另一个POST请求,即start请求启动容器。这时docker daemon执行start.go,在宿主机创建容器,同时执行execdriver的run方法,配置namespace、cgroups、挂载rootfs
docker daemon与操作系统的交互完全由execdriver执行,docker daemon只提供了commandv、pipes、startCallback三个参数,分别是配置信息、重定向信息和回调方法
Libcontainer - docker中的容器管理和启动包
docker execdriver使用了Libcontainer包内容进行容器管理和启动。execdriver中维护了一个容器配置模板对象container,它不是真正的物理容器,而是作为libcontainer与docker daemon之间信息交换的标准格式。
libcontainer的工作方式
execdriver调用libcontainer加载容器的流程可以概括为三个步骤:
Process:创建libcontainer构建容器所需的进程对象,设置容器的输出管道
Factory:通过
factory.Create创建一个逻辑容器Container,将容器配置模板container填充到Container的config项里Container:执行
Container.start启动物理容器,execdriver执行Docker daemon提供的startCallback完成回调,并执行Process.Wait等上述Process所有工作完成
用Factory创建逻辑容器Container
包括验证配置、容器ID、根目录的合法性,创建容器工作目录(/var/lib/docker/containers/<容器ID>)等
启动逻辑容器Container
参与物理容器创建的Process一共有两个实例,一个是Process用于物理容器内进程配置和IO管理,即前面讲到Process流程中创建的Process,另一个叫ParentProcess,负责从物理容器外部处理物理容器启动工作,与Container对象直接交互。启动后ParentProcess还要负责执行等待、发信号、获取容器内进程PID等管理工作
实际上,ParentProcess是一个接口,真正创建出来的实例称为initProcess,里面实际上包括cmd、pipe、cgroup管理器和容器配置4块。initProcess.start执行意味着物理容器真正诞生。
用逻辑容器创建物理容器
initProcess.start执行后,开始执行一些PID存入cgroup、网络配置、管道配置等工作
docker daemon和容器之间的通信方式
容器启动后就是要了namespace隔离,把负责创建容器的进程称为父进程,容器进程称为子进程,二者的通信实际上也通过namespace隔离了。让父子进程通信的方案一般有四种:发送信号通知(signal)、对内存轮询访问(poll memory)、sockets通信(sockets)、文件和文件描述符
docker是通过管道—文件和文件描述符的方式。通过打开一个pipe,子进程内嵌文件描述符,父子之间就可以通过读文件写入内容进行通信。这个通信完成的标志在于EOF信号传递。
Docker镜像管理
rootfs是docker镜像的文件内容以及一些运行docker容器的配置文件一起组成的静态文件系统运行环境。可以这么说:docker镜像是docker容器在一个时间点上的静态切面视角,docker容器是docker镜像的运行状态
docker镜像的主要特点
分层
每个镜像都由一些列镜像层组成。怎么理解呢,比如redis镜像可能依赖下载的时候可能出现:
afb6ec6fdc1c: Already exists
608641ee4c3f: Pull complete
668ab9e1f4bc: Pull complete
78a12698914e: Pull complete
d056855f4300: Pull complete
618fdf7d0dec: Pull complete这其实就是分层的表现。例如我基于ubuntu系统开发了一个封装了python运行环境,且实现了安全补丁的新镜像,那么这个镜像有三层,第一层是ubuntu,第二层是python,第三层是安全补丁。
这么做的好处是使镜像更轻量化。如果两个镜像底层都依赖相同的镜像,就无需重复下载底层镜像。此外使用docker commit提交修改时,只需要修改最上方的读写层即可。
怎么理解呢?回想之前提到的:镜像是容器在一个时间点上的静态切面。也就是说镜像里面其实就包含了一个下载了基础运行环境(例如ubuntu)的文件系统。如果基于一个ubuntu镜像安装python,并制作新镜像,就相当于一个ubuntu文件系统+一个python文件系统叠加在一起生成的最终文件系统。这叫联合挂载。
举个例子:
ubuntu的基础文件系统中存在:/bin、/dev、/etc、/home等目录
基于python开发后有/work目录
现在要开发安全组件了,要先下载前两层镜像,当下载了这个最终文件系统,并且启动成容器,联合挂载技术会将下面这两层当成只读层,并且在上面挂载一个空的读写层,这样新增的安全补丁就可以只在最上方读写层修改,不影响下面两层
最终用户视角的文件系统是/bin、/dev、/etc、/home、/work
写时复制 - copy on write
如果多个容器公用了一个底层镜像,那么在启动时其实是不需要复制多份底层镜像的。而是以只读方式挂载到对应的挂载点,在上面覆盖各自的读写层。未更改内容时,所有容器共享同一份数据。只有在容器运行时文件系统发生变化了,才会把变化的文件系统写到可读写层,并隐藏只读层中的老版本文件。好处是减少镜像对磁盘占用,缩短启动时间。
内容寻址
基于镜像层内容生成内容哈希,作为唯一标志,减少ID冲突,增强镜像层共享
docker镜像的存储组织方式
registry
镜像仓库,类似于git仓库,保持镜像、镜像层次、元数据。可以搭建私有registry,也可以使用docker官方公用registry。公用redistry可以添加代理或者镜像地址使下载更顺畅
在etc/docker目录下面
// 创建daemon.json文件
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://do.nark.eu.org",
"https://dc.j8.work",
"https://docker.m.daocloud.io",
"https://dockerproxy.com",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.nju.edu.cn"
]
}
EOF
// 重启daemon守护进程和docker
systemctl daemon-reload
systemctl restart docker
这里如果restart不生效,可以先stop再start
systemctl stop docker.socket
systemctl stop docker
systemctl start docker
// 查看镜像源生效
docker versionrepository
repository是具有某个功能的docker镜像所有迭代版本的镜像组。因此registry是repository的集合体。例如ubuntu的repository包含ubuntu:14.04、ubuntu:12.04。
repository还参与组织用户仓库命名:username/repository_name
manifest
描述文件,存储元数据文件
image和layer
iamge用来存储一组镜像相关的元数据信息,layer是镜像层
dockerfile
通过docker build命令构建镜像时需要用到的定义文件。通过DSL语法定义镜像。
docker镜像构建操作
docker构建一个镜像都是基于另一个镜像开始的,不可能无中生有。最最底层的镜像被称为基础镜像,例如ubuntu、Fedora等,基础镜像是构建镜像的起点
构建镜像有两种方法:commit和build
commit
docker commit是通过将一个容器在当前时间点留下一个快照,打包成镜像。实际上它只提交容器镜像发生变更的部分。
build
docker build <options> <PATH | URL | ->docker build是在一个镜像的基础上构建镜像。一般用于新镜像生成。其中PATH | URL是镜像的上下文,其中要包含dockerfile及其他资源文件,可以为 - ,有四种情况:
上下文为“-”:即没有context,从STDIN读取
sudo docker build - < Dockerfile # 读取dockerfile
sudo docker build - < context.tar.gz # 读取压缩的上下文上下文为URL,且是
git repository URL
sudo docker build github.com/creack/docker-firefox上下文是URL,但不是
git repository URL,则从该URL下载context,封装成io流其他情况,即context为本地文件或目录,可以用
.dockerignore排除文件
sudo docker build -t vieux/apache:2.0
sudo docker build -f /home/me/myapp/dockerfiles/debugdocker镜像分发
包括线上分发的docker push和docker pull,以及线性分发的docker save和docker load
Docker存储管理
docker镜像元数据存储
repository元数据存储本地持久化存储在
/var/lib/docker/image/<some_graph_driver>/repositories.jsonimage元数据存储在
/var/lib/docker/image/<graph_driver>/imaged/content/sha256/<image_id>layer元数据存储在
/var/lib/docker/image/<graph_driver>/layerdb/sha256/<chainID>docker存储驱动
前面镜像元数据存储部分,路径下面都有一个graph_drvier,就是对应的存储驱动。有三种常用的:aufs、overlay、devicemapper。在启动docker服务时可以指定存储驱动:
docker daemon -s some_driver_nameaufs
是一种支持联合挂载的文件系统,支持将多个目录挂载到同一个目录下。通常只有最上层是可读写层。下层是只读层。
aufs相关目录有两个:
/var/lib/docker/image/aufs # 存放镜像元数据
/var/lib/docker/aufs # 基础路径在基础路径下还可以找到diff、layers、mnt三个目录:
mnt:aufs的挂载目录
diff:实际数据来源,包括只读层可写层,最终都挂载在mnt上的目录
layers:与每层依赖有关的层描述文件
devicemapper
linux2.6提供的一种从逻辑设备到物理设备的映射框架机制。包括三个概念:映射设备、映射表、目标设备。Device Mapper本质就是根据映射关系描述IO处理规则,当映射设备接收到IO请求,这个IO请求会根据映射表逐级转发,指导最底层物理设备。
/var/lib/docker/devicemapper # 基础路径在这个基础路径下也有mnt、metadata、devicemapper
mnt:设备挂载目录
devicemapper:存储loop-lvm模式下两个稀疏文件
metadata:存储每个块设备驱动层的元数据信息
overlay
一种新型联合文件系统
Docker数据卷
volume机制用于挂载数据卷
数据卷的使用方式
创建和挂载volume
sudo docker volume create --name vol_simple创建的卷位于
/var/lib/docker/volume目录下,其中vol_simple是其下级目录。
使用-v可以挂载volume,当要挂载的volume不存在,自动创建
sudo docker run -d -v /data ubuntu /bin/bash # 创建一个随即名字的卷挂载到ubuntu容器/data
sudo docker run -d -v vol_simple:/data ubuntu /bin/bash # 把vol_simple挂载到ubuntu容器/data使用inspect命令也可以获取卷信息
sudo docker volume inspect vol_simple挂载的目录也可以是宿主机自行指定的目录
sudo docker run -d -v /tmp/gty:/data ubuntu /bin/bash也可以挂载指定文件
sudo docker run -it --name vol_file -v /tmp/gty/file1:/data/file1 ubuntu /bin/bash可以使用:ro指定只读,使用:z和:Z指定是否共享,z是默认共享
sudo docker run -d -v /tmp/gty:/data:ro ubuntu /bin/bash
sudo docker run -d -v /tmp/gty:/data:Z ubuntu /bin/bash使用dockerfile添加卷
使用VOLUME命令可以添加
VOLUME /data # 添加一个随机命名的卷
VOLUME [“/data1”, “/data2”] # 添加两个随机命名的卷但是VOLUME命令不能挂载宿主机的指定文件夹,这是为了防止镜像在别的机器上运行,没这个路径
VOLUME挂载的卷不能做后续修改,除非先改再挂:
# 先挂再创建文件,不生效
FROM ubuntu
RUN useradd foo
VOLUME /data
RUN touch /data/file
# 先创建文件再挂,生效
FROM ubuntu
RUN useradd foo
RUN mkdir /data && touch /data/file
VOLUME /data共享volume
使用--volumes-from可以做多容器共享一个卷
删除volumes
docker volume rm <volume_name> # 删除指定卷
docker run --rm …. # 在容器停止时删除容器以及容器挂载的volumeDocker网络
network模式 - CNM模型的基本架构
CNM模型是docker容器的虚拟化网络模型,通过libnetwork库提供了一些网络驱动的标准化接口和组件。
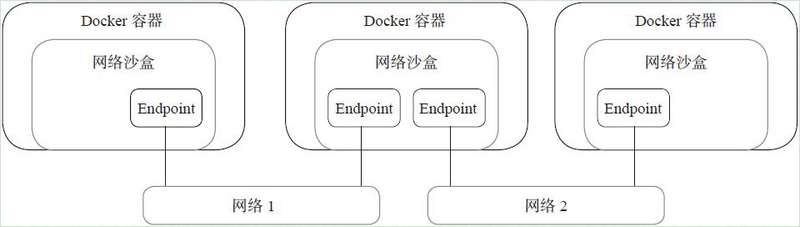
CNM模型中有三个组件:sandbox、endpoint、network;提供了五类驱动。
sandbox:沙盒,一个沙盒包含一个网络栈的信息。创建pod时县创建sandbox环境,为容器设置网络环境,例如分配IP、容器接口、路由、DNS设置等
endpoint:端点,一个endpoint只能加入一个sandbox和一个网络
network:网络,一个网络是一组可以直接互相联调的endpoint
五类驱动模式:
bridge驱动:桥接模式,只是容器间通信的简单方案,跟外界通信要通过NAT技术
host驱动:主机模式使pod运行在宿主机网络环境,主要解决容器与外界通信地址转换问题,可以直接使用宿主机IP进行通信。但是会降低pod与pod之间的隔离性,不适合大集群
overlay驱动:覆盖网络模式,支持多宿主机容器的互联
remote驱动:支持用户自行实现的网络驱动插件调用
null驱动:不给容器做任何网络配置,支持自定义能力
构造一个基于bridge的网络栈
基于模型如下:
补图https://blog.csdn.net/qq_34556414/article/details/108228226
创建backend和fronted两个网桥
sudo docker network create backend
sudo docker network create frontend使用如下命令可以查看网络创建结果及删除网络:
docker network ls
docker network rm其中也可以看到docker daemon默认创建的三种驱动网络
创建容器挂载网络:
sudo docker run -it --name container1 -- net backend busybox
sudo docker run -it --name container2 -- net backend busybox
sudo docker run -it --name container3 -- net fronted busybox这时在container1和container2中互ping就会发现是通的,但是ping容器3就不通了。
在container2中使用ifconfig命令可以查看网卡情况,可以看到etho0网卡和网桥backend在同一个IP段,这个网卡就是一个endpoint
给container2再加一个fronted网络段:
sudo docker network connect fronted container2再去container2查看ifconfig,可以看到网卡多了一个eth1,IP和网桥fronted在一个IP段,且ping容器3就已经通了
network模式 - bridge驱动(桥接模式)
桥接网络是最常见的Docker网络类型之一,它为容器提供了一个虚拟的网络桥接器,将多个容器连接到同一个网络中。这使得容器可以通过在同一网段内的IP地址相互通信
docker0网桥
在一台未经过配置的Ubuntu机器上安装完docker后,在宿主机上使用ifconfig查看网卡,会发现有一个docker0网卡,假设IP为172.17.0.1/16,那么这块网卡也会在内核路由表上添加一条到达相应网络的路由:
route -n
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0即标识所有目的IP地址为172.17.0.0/16的数据包从docker0网卡发出。
创建一个con1容器,它就有l0和eth0两个网卡,l0是回环网卡,etho0是容器与外界通信的网卡。假设eth0的IP为172.17.0.2/16,这和宿主机docker0网卡是同一个网段的,则这两个网卡之间就是互通的。
这里网桥就类似交换机的功能,为连接在上面的设备转发数据帧
iptables规则
docker安装后在宿主机上会加一些列iptables规则,用于docker容器和容器、容器和外界的通信。使用如下规则:
iptables-save可以看到有一条规则:
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE这是一条NAT规则,是将172.17.0.0/16这个网段的数据包,即所有容器发出的数据,做SNAT转换。这样一来,从docker容器访问外网的流量从外部看来都是宿主机发出的,外部就感知不到docker容器存在。
反过来,如果是容器提供服务,暴露了5000端口:
sudo docker run -d -p 5000:5000 training/webapp python app.py在iptables中可以看到如下配置:
-A DOCKER ! -I docker0 -p tcp -m tcp --dport 5000 -j DNAT --to-destination 172.17.0.4:5000即把宿主机5000的流量通过DNAT转发到对应容器的5000端口上。且docker默认的外部访问规则是允许所有IP访问,可以通过iptables添加规则限制,例如8888ip访问:
iptables -I DOCKER -I docker0 ! -s 8.8.8.8 -j DROPDNS
docker容器的DNS是可以启动后被虚拟文件覆盖的,实现DNS及时更新,即/etc/resolv.conf
network模式 - 其他驱动
hsot驱动(主机模式)
主机网络是另一种网络类型,它将容器直接连接到宿主机的网络栈中,使得容器与宿主机共享同一个网络命名空间。这在一些特定场景下非常有用,如需要容器与宿主机共享相同的IP地址
# 启动一个容器,并使用主机网络模式
docker run -d --name host_network_container --network host nginx
# 在 host_network_container 容器中,可以直接访问宿主机的网络
docker exec -it host_network_container ping google.comoverlay驱动(覆盖网络)
覆盖网络是用于实现多主机间容器通信的一种网络类型。Overlay网络允许不同宿主机上的容器在逻辑上组成一个网络,使得容器可以像在同一主机上一样进行通信。
# 在多个主机上创建一个Overlay网络
docker network create --driver overlay my_overlay_network
# 在不同主机上分别启动容器,并将它们连接到 Overlay 网络
# 这些容器将通过 Overlay 网络进行通信,而无需考虑它们在不同主机上
docker service create --name service1 --network my_overlay_network nginx
docker service create --name service2 --network my_overlay_network nginxlink模式
link模式已经很少使用了,并且即将废弃了
# 先启动container1
docker run -d --name db_container -e MYSQL_ROOT_PASSWORD=password mysql:latest
# 启动container2链接到1
docker run -d --name web_app_container --link db_container:db -p 8080:80 web_app:latest这种模式下,容器间的连接只能是单向的,如果容器名改变,连接也会失败。
使用link连接后,docker容器里面会设置一个<alias>_NAME环境变量,,同时在/etc/hosts文件中会添加对应的路由
Docker与容器安全
docker的安全机制
docker daemon安全
对于docker服务,使用Unix域套接字与客户端进行交互,只有进入daemon宿主机所在机器并且有权限访问daemon套接字才能与daemon建立联系
镜像安全
通过login对push和pull进行权限访问控制,对镜像有manifest文件做签名使用
内核安全
通过cgroups对资源进行限制,防止资源抢占和过量申请
namespace作为隔离容器与容器、容器与宿主机的屏障
网络安全
通过--icc可以紧致容器与容器之间通信,也可以通过设置iptabels调整访问策略
安全特性支持
对seccomp的支持、对SELinux的限制(限制ssh)
评论区