


连接简述
连接就是两个表的查询结果做笛卡尔积
连接分为内连接和外连接,内连接指的是两表连接时,只有一边有的数据不记入结果,外连接是只有一边有的数据记入结果
因此外连接还分为左外连接、右外连接、全外连接,分别为左表有的数据一定记入结果、右表有的数据一定记入结果、左右表有的数据一定记入结果
连接的语法如下:
SELECT * FROM t1 [LEFT/RIGHT/FULL] [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件];where连接默认是内连接,与
INNER JOIN ON/JOIN ON/CROSS JOIN效果是一样的使用JOIN ON语法时,加LEFT、RIGHT都是外连接,分别为左外和右外连接,加FULL是全外连接,其中OUTER可以省略不写
连接的原理
驱动表和被驱动表
连接本质上可以视为查询两次,如下语句:
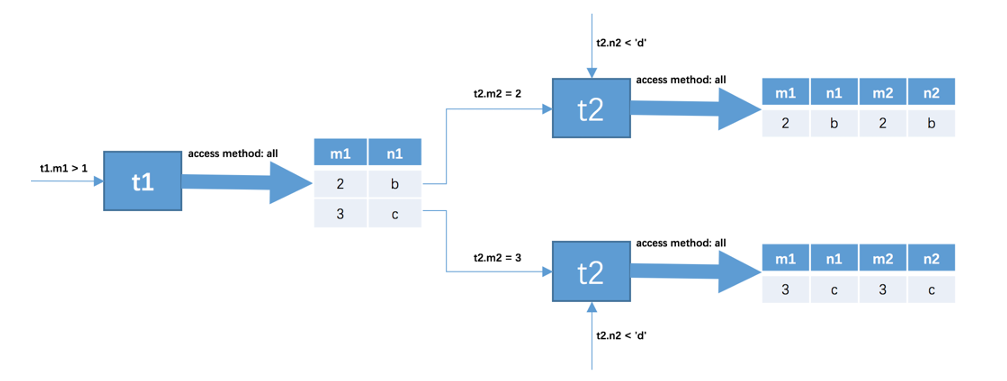
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd'表t1和t2连接,通过WHERE条件进行,则一定是内连接,按照t1和t2的顺序,引擎会先去t1按照条件查询
即执行SELECT * FROM t1 WHERE t1.m1 > 1
假如得到两条记录,t1.m1的值分别为2、3
然后引擎会执行两条sql:SELECT * FROM t2 WHERE t2.m2 = 2 AND t2.n2 < 'd' 以及SELECT * FROM t2 WHERE t2.m2 = 3 AND t2.n2 < 'd'
这时候,t1查询一次,t2查询两次,t1是驱动表,t2是被驱动表
驱动表和被驱动表的概念不是固定的,而是互相的,假如t1、t2、t3三表查询,则t2可能是t1的被驱动表,又可能是t3的驱动表
结合内连接和外连接的概念来看,内连接和外连接的根本区别就是在驱动表中的记录不符合 ON 子句中的连接条件时不会把该记录加入到最后的结果集
因此:
使用where的时候或JOIN ON的内连接写法时,驱动表是可以互换的,不影响结果
左外连接和右外连接,驱动表是不能互换的,按照是左还是右外连接的语法,引擎自己选择左表或右表为驱动表
嵌套循环连接
前面已经得知,驱动表只访问一次,而被驱动表可能访问多次,其访问次数取决于驱动表执行单表查询后结果集中的条数
这就像是我们在开发代码时写了一个for循环嵌套,因此这种连接又叫嵌套循环连接
如果是三表连接,t2又变成t3的驱动表,每一次t2的访问又会带来n次t3的访问,那就是三层for循环嵌套,这个性能肯定哗哗的下降
使用索引加快连接速度
回到前面那个例子,对于t2的查询语句等价于SELECT * FROM t2 WHERE t2.m2 = 2 AND t2.n2 < 'd'
假设在t2表中,m2是主键列,或UNIQUE KEY,这种场景在单表查询里面就是const方法,理应是最快的
其实在连接查询里面也是最快的,只是不叫const,而是叫eq_ref
而假设n2列是普通二级索引,则该语句使用的方法就是range
因此可以得到以下结论:
对连接条件建立索引,能够提升连接查询的执行效率
尽量避免
SELECT *,把需要获取的列拿出来,构造联合索引,最不济也能匹配到index方法,遍历索引列,而不用全表扫描
连接缓存
如果先查出驱动表的数据,再按照记录数执行被驱动表的查询,那么每一次查询,都要拿一批被驱动表的数据扫一次,难免会导致被驱动表.ibd文件被多次加载到内存、执行查询
因此MySQL对这种情况做了优化,在内存中申请了一块区域,叫join buffer,里面存放驱动表的数据,然后扫描被驱动表,与其中的多条驱动表数据进行匹配
即假设驱动表有4条数据,正常要查4次被驱动表,如果join buffer可以放2条缓存,则只查2次就可以了
那如果join buffer足够大,把4条全存进去了,只需要1次就可以执行完连接查询了
基于该join buffer的查询叫基于块的嵌套连接 (Block Nested-Loop Join)算法
该区域可以通过系统变量join_buffer_size 进行配置,默认大小为 262144字 节 (也就是 256KB ),最小可以设置为 128字节
当然,修改join buffer只是一种优化连接查询的备选方案,更优秀的解决还是优化索引,让表查起来更快一些
评论区