


kafka的一些设计理念
这是理解 Kafka 所有机制的基石。Kafka 的核心存储结构是一个只能追加(Append-Only)的、有序的、不可变的(Immutable)消息序列,即日志(Log)。
顺序读写:磁盘顺序读写的性能(甚至超过内存随机读写)是 Kafka 高吞吐量的根本保障。所有消息都被顺序追加到文件末尾,极大地减少了磁盘寻道时间。
不可变性:消息一旦写入就不能被修改。这简化了并发控制(不需要复杂的锁机制)、保证了消息顺序,并使得缓存(PageCache)策略非常高效。
日志分段(Log Segment):一个主题分区(Partition)的日志在物理上被切分为多个段文件(Segment)(包括
.log数据文件和.index、.timeindex索引文件)。活跃的写入只会发生在最后一个段(Active Segment)。老的段文件会被定期清理或压缩(Compaction)。
kafka的分区分段机制可以与Pulsar做对比,参考如下:
http://www.chymfatfish.cn/archives/pulsar#%E5%88%86%E6%AE%B5%E3%80%81%E5%88%86%E5%8C%BA
Kafka的设计架构
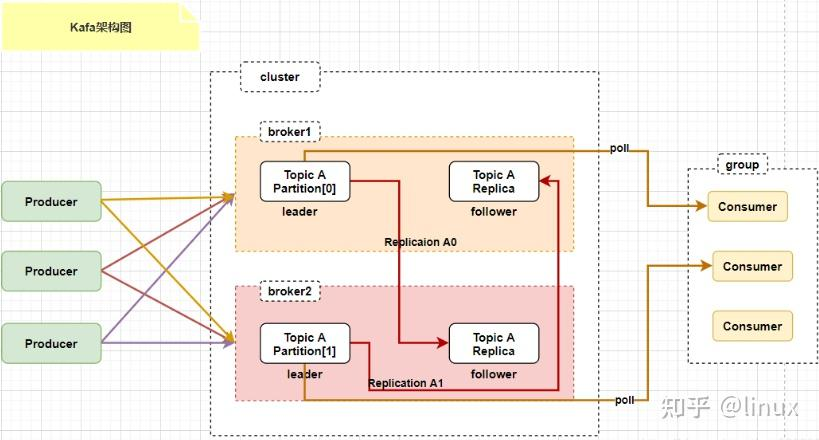
存储机制:高效的“消息数据库”
物理存储结构
Topic -> Partition -> Segment: 一个 Topic 分为多个 Partition,每个 Partition 是一个逻辑日志,物理上由多个 Segment 文件组成。
索引(.index & .timeindex): 为了快速定位消息,Kafka 为每个 Segment 维护了稀疏索引。
.index文件:映射offset->物理位置(position)。.timeindex文件:映射时间戳->offset。稀疏索引意味着它不会为每条消息建索引,而是隔几条消息建一个。查找时,先通过索引找到大致范围,再顺序扫描一小段数据,这是一种空间换时间的经典设计。
每个partition都是有序的,顺序就是消息被追加的顺序,每个partition上的每个消息都被赋了topic中唯一的offset值,当consumer每消费一个partition的消息,offset就会+1,consumer也可以跟踪和重设这个offset值,从而读取任意位置消息
topic里面的消息是无状态的,因此topic消息的过期只针对时间。可以设置这个过期时间从而达到释放磁盘空间的目的。
页缓存(PageCache)与零拷贝(Zero-Copy)
这是 Kafka 实现高吞吐的两大“杀手锏”。
页缓存(PageCache):
Kafka 大量依赖操作系统本身的页缓存(PageCache)来缓存磁盘数据,而不是在 JVM 堆内维护缓存。这避免了昂贵的 GC 开销和对象开销。
写入时:消息先被写入页缓存,由操作系统异步刷盘。
读取时:优先从页缓存中读取,如果命中则速度极快。
零拷贝(Zero-Copy):
传统数据发送:
磁盘 -> 内核缓冲区 -> 用户缓冲区 -> 内核Socket缓冲区 -> 网卡。经历了多次上下文切换和数据拷贝。Kafka 的零拷贝:使用
sendfile()系统调用,数据直接从页缓存发送到网卡, bypass 了应用程序(用户空间)。上下文切换次数和数据拷贝次数大幅减少,极大提升了消费效率。
生产者(Producer)机制
分区策略(Partitioning)
生产者决定将消息发送到哪个分区,这是实现负载均衡和语义保证的关键。
DefaultPartitioner:如果指定了
key,则对key进行哈希(murmur2Hash),然后对分区数取模,确保相同 key 的消息总是进入同一分区,从而保证顺序性。如果没有指定
key,则使用轮询(Round-Robin) 策略将消息均衡地分发到所有分区。
内存缓冲与批量发送(Batching)
生产者并非来一条消息就发一条,而是先存入内存缓冲区(RecordAccumulator)。
批次(Batch): 发往同一分区的消息会被聚合成一个 Batch。
触发条件: 发送由两个参数控制,满足任一即发送:
linger.ms: 等待时间。即使 Batch 没满,也等待这么久后发送,旨在增加批量处理的几率。batch.size: Batch 的大小。Batch 满了就立即发送。
优点: 大幅减少网络 IO 次数,极大提升吞吐量。
以Batch的方式推送数据可以极大提高处理效率,producer可以将消息在内存中累计到一定数量再以batch发送请求,大小可自定,这里对IO的性能提升较大。
消息确认机制(Acks)
acks 参数决定了生产者认为请求完成的标准,这是在可靠性和延迟之间的权衡。
acks=0: “发后即忘”。不管是否成功写入服务器,立即视为发送成功。吞吐量最高,但可能丢失消息。acks=1(默认): Leader 副本成功写入本地日志即视为成功。平衡了吞吐和可靠性,但如果 Leader 刚写入就宕机且未同步到 Follower,消息仍会丢失。acks=all(或acks=-1): 最强保证。要求 Leader 收到所有 ISR(In-Sync Replicas) 副本的成功写入确认后才视为成功。可以保证只要至少一个 ISR 副本存活,消息就不会丢失。
producer可以异步发送消息并且得到一个Future结果,返回的是offset或者发送异常。异步流程有一个ack参数,代表producer等待broker发送成功回应的数量。ack=0时,producer不等待broker响应,这时吞吐量达到最大;ack=1时,producer等待一个partition副本收到消息就会收到broker确认,兼顾性能和可靠性;ack=-1时,producer等待所有备份的partition副本收到消息时得到broker的确认。
消费者(Consumer)机制
消费者组(Consumer Group)与重平衡(Rebalance)
消费者组(Consumer Group): 多个消费者实例可以组成一个组来共同消费一个 Topic。
核心规则: 一个分区只能被组内的一个消费者消费;一个消费者可以消费多个分区。
这是实现横向扩展和负载均衡的基础。
consumer需要关注与consumer group的特性:
如果所有的消费者实例在同一个消费组中,消息记录会负载均衡到消费组中的每一个消费者实例
如果所有的消费者实例在不同的消费组中,则会将每条消息记录广播到所有的消费组或消费者进程中
重平衡(Rebalance):
定义: 当消费者组成员发生变化(增、删、崩溃)或订阅的 Topic 分区数发生变化时,分区所有权在消费者间重新分配的过程。
影响: Rebalance 期间,整个消费者组会停止工作(Stop-The-World),是影响稳定性的一个重要因素。
触发条件: 消费者心跳超时(
session.timeout.ms)、处理消息超时(max.poll.interval.ms)等。
api:consumer有两套API:high-level api和Sample-api。
Sample-api维护了与单个broker之间的链接,且不做状态维护,每次pull都需要指定offset值,因此比较灵活,可以自由决定消费哪个消息;high-level api封装了对集群中一系列broker的访问,提供黑盒消费一个topic的能力,且维护已消费状态,不需要单独指定offset,每次消费都是下一个消息。
high-level api还支持consumer以组的形式消费topic,如果多个consumer有一个共同的组名,则各个consumer均衡地进行消费,类似一个消息队列服务;如果多个consumer消费一个topic但是组名不同,那么kafka将消息广播到每一个组,类似广播服务。
位移管理(Offset Management)
消费者需要记录自己消费到了哪个位置,这个位置叫位移(Offset)。
提交(Commit): 消费者需要定期将自己消费到的位移提交到 Kafka 一个特殊的内部 Topic(
__consumer_offsets)中。交付语义(Delivery Semantics):
至少一次(At least once): 消息绝不会丢,但可能重复消费(先提交位移后处理业务,若处理中途崩溃,重启后会从已提交的位移处重新消费)。
至多一次(At most once): 消息可能丢失,但绝不会重复(先处理业务后提交位移,若处理完提交前崩溃,消息就丢了)。
精确一次(Exactly once): 通过事务机制和幂等生产者实现,消息且只被处理一次。实现复杂,开销较大。
副本(Replication)与高可用机制
这是 Kafka 实现故障自动转移(Failover)和数据可靠性的核心。
Leader/Follower 模型
每个 Partition 有多个副本(Replica),分散在不同 Broker 上。
只有一个副本是 Leader,负责所有客户端的读写请求。
其他副本都是 Follower,只做一件事:从 Leader 异步拉取(Fetch)消息,同步到自己的日志中。
replications是topic的副本数量,即指定几个broker存放topic数据,提供了kafka的高可用性
partitions是topic的组成片的数量,producer产生数据会按照一定规则发布到各个partition中,只有一个partition的副本会被选举为leader进行读写
建议partition数量大于broker数量,这样leader partition就会均匀分布在各个broker中
ISR(In-Sync Replicas)机制
ISR: 与 Leader 副本保持同步的副本集合(包括 Leader 自己)。
同步标准: Follower 副本的落后程度(
replica.lag.time.max.ms)不能超过一定阈值。如果 Follower 在指定时间内未能追上 Leader,就会被踢出 ISR。核心作用:
决定
acks=all的成功条件。选举新 Leader: 当 Leader 宕机时,新的 Leader 必须从 ISR 中选举产生,这样才能保证数据一致性(不丢消息)。
控制器(Controller)与 Leader 选举
控制器(Controller): Kafka 集群中唯一的一个特殊 Broker(通过 ZooKeeper/KRaft 竞选产生),负责管理集群状态。
职责:
管理分区和副本的状态(如创建、删除)。
监听 Broker 变化,在 Leader 副本宕机时,负责从 ISR 中为受影响的分区选举新的 Leader。
触发重平衡。
高可用: 如果 Controller 所在 Broker 宕机,其他 Broker 会通过 ZooKeeper/KRaft 重新选举出新的 Controller,保证管理功能的高可用。
kafka高级特性
压缩
当以batch发送消息时,producer端可以通过GZIP或Snappy格式对消息集合进行压缩,从而降低网络IO压力
consumer端会通过kafka消息头部添加的一个描述压缩属性的字节后两位编码判断压缩方法,为0是不压缩
消息可靠性
从producer端看,可以通过设置ack属性,等待broker反馈后再发送下一个,甚至可以调整参数使所有备份partition副本都收到消息再发下一个
从consumer端看,可以通过回退offset属性重新消费上一个消费失败的消息
备份机制
备份机制可以让一个n个节点的集群在挂掉n-1个后还能正常运行。
在所有备份节点中有一个leader节点,它保存了其他备份节点列表,并维持各个备份间的状态同步
当leader节点挂了,controller在zk中的监视器将消息发送给controller,controller开始执行新leader的选举工作
kafka是基于ZK进行故障恢复选举,而ZK是基于zab算法的,参考zk部分:
KafkaAdmin源码分析
AdminClient
create
AdminClient#create方法是kafka构造Admin的API的最上游,给用户直接使用
return (AdminClient) Admin.create(props);
// -- Admin#create --
return KafkaAdminClient.createInternal(new AdminClientConfig(props, true), null);KafkaAdminClient
createInternal - 构造KafkaAdmin的方法
networkClient = new NetworkClient(……关注点1:这里构造了一个kafkaClient,客户端,对应kafka服务器做连接
return new KafkaAdminClient(config, clientId, time, metadataManager, metrics, networkClient, timeoutProcessorFactory, logContext);关注点2:之类初始化了KafkaAdminClient管理器,这个构造方法是真正初始化的地方
构造方法
this.runnable = new AdminClientRunnable();
……
this.thread = new KafkaThread(threadName, runnable, true);
……
thread.start();构造方法中除了参数构造,还启动了一个AdminClientRunnable的线程,可以进一步看看这个可执行对象都是在执行些什么内容
listTopics - 获取全部topics的用户接口
runnable.call(new Call("listTopics", calcDeadlineMs(now, options.timeoutMs()),
new LeastLoadedNodeProvider()) {
……
MetadataRequest.Builder createRequest(int timeoutMs) {
return MetadataRequest.Builder.allTopics();
}方法中通过kafka预置的请求创建工具创建了一个allTopics请求,通过call方法,存入newCalls中,等待异步发送
AdminClientRunnable
核心成员变量包括:
// 还没进入发送流程的新请求
private final List<Call> newCalls = new LinkedList<>();
// 尚未分配到节点的客户端请求,马上就要找node发送
private final ArrayList<Call> pendingCalls = new ArrayList<>();
// 已经分配好了节点的请求
private final Map<Node, List<Call>> callsToSend = new HashMap<>();
// 已经标记为已发送的请求
private final Map<String, Call> callsInFlight = new HashMap<>();通过这几个list可以看出来kafka客户端提交请求和发送请求是异步的流程
run
processRequests();重点关注其中调用的方法,下面finally是处理异常关闭
processRequests - 不断拉取并发送请求到服务器
while (true) {
drainNewCalls();通过while true启动了一个发送请求的工作循环,可以看出来只要kafka在本地被构造出来,就会不断循环处理客户端的请求发送到服务器
首先通过drainNewCalls方法从newCalls里面提取请求,存入pendingCalls里面等待发送。这里可以看出来,捞取请求的线程和存入请求的线程并不是一个,因此kafka创建请求和发送请求是一个异步的流程
timeoutPendingCalls(timeoutProcessor);
timeoutCallsToSend(timeoutProcessor);
timeoutCallsInFlight(timeoutProcessor);这里对pendingCalss、callsToSend、callsToFlight做超时处理
pollTimeout = Math.min(pollTimeout, maybeDrainPendingCalls(now));然后调用maybeDrainPendingCalls方法,检查pendingCalls里面的请求是否可以分配上节点,分配的上的,转移到callsToSend中
long metadataFetchDelayMs = metadataManager.metadataFetchDelayMs(now);
if (metadataFetchDelayMs == 0) {
Call metadataCall = makeMetadataCall(now);
if (!maybeDrainPendingCall(metadataCall, now))
pendingCalls.add(metadataCall);然后这里判断是否需要获取元数据信息,如果需要则重新构造一个获取元数据信息的请求,然后看下能不能分配节点,能分配直接进callsToSend里面,分配不了,先扔进pendingCalls里面,下次再拉取更新。
pollTimeout = Math.min(pollTimeout, sendEligibleCalls(now));然后完成calls的发送,发送完成后转移到callsToFlight
List<ClientResponse> responses = client.poll(Math.max(0L, pollTimeout), now);最后,kafka客户端获取响应,在poll方法中进行了连接的初始化,可以溯源方法调用,一直到NetworkClient#initiateConnect
maybeDrainPendingCalls
Iterator<Call> pendingIter = pendingCalls.iterator();
while (pendingIter.hasNext()) {
……
maybeDrainPendingCall(call, now)maybeDrainPendingCall
Node node = call.nodeProvider.provide();
if (node != null) {
……
getOrCreateListValue(callsToSend, node).add(call);可以分配节点,这里就调用getOrCreateListValue方法,实际上调用的是map的computeIfAbsent方法,添加到callsToSend里面
NetworkClient - kafka客户端
initiateConnect - 初始化连接
connectionStates.connecting(nodeConnectionId, now, node.host());这里可以看到,node是在这个方法调用的时候就已经传进来的,这个时候选定了一个要连接的node,可以获取到这个node的所有信息,直接做连接就可以了。
那么node是如何获取到的呢?从该方法的调用点向上找,在maybeUpdate方法中找到这一个调用:
// -- maybeUpdate --
Node node = leastLoadedNode(now);leastLoadedNode - node选取负载均衡
该方法其实是在做类似负载均衡操作,看上面的简介就可以知道:
Choose the node with the fewest outstanding requests which is at least eligible for connection选择完成请求最少的node
List<Node> nodes = this.metadataUpdater.fetchNodes();首先拿到所有node的列表
生成一个索引,遍历node
int idx = (offset + i) % nodes.size();
Node node = nodes.get(idx);
if (canSendRequest(node.idString(), now)) {
……
return node;通过canSendRequest做判断,可以请求,就把这个node返回去。这里体现了Kafka的多备份、集群化的特点。
selector.connect(……完成连接
KafakProducer源码分析
KafkaProducer
send/doSend - 发送事件统一用户接口
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());首先完成消息体的序列化
RecordAccumulator.RecordAppendResult result = accumulator.append(record.topic(), partition, timestamp,
serializedKey,
serializedValue, headers, appendCallbacks, remainingWaitMs, abortOnNewBatch, nowMs, cluster);这里是kafka以batch发送消息部分代码,使用累计器进行累计
kafkaConsumer源码分析
KafkaConsumer
poll - 拉取事件的用户API
return poll(time.timer(timeout), true);从这里隐约可以看出来是走的timer定时任务
final Fetch<K, V> fetch = pollForFetches(timer);拉取的核心方法在这里
pollForFetches
sendFetches();这里首先调用sendFetches发送拉取topic的请求
client.poll(pollTimer, () -> {
return !fetcher.hasAvailableFetches();
});最后这里的client调用到ConsumerNetworkClient和前面admin的
NetworkClient类似,可以看出来也是个异步的流程
ConsumerNetworkClient
poll
long pollDelayMs = trySend(timer.currentTimeMs());在poll方法中首先完成发送
client.poll(pollTimeout, timer.currentTimeMs());调用client#poll方法完成response拉取。这里是NetworkClient,不是ConsumerNetworkClient了。
send
ClientRequest clientRequest = client.newClientRequest(node.idString(), requestBuilder, now, true,
requestTimeoutMs, completionHandler);
unsent.put(node, clientRequest);send本身也是异步的,先把准备好的request放到unsend列表里面
Fetcher
sendFetches
final FetchRequest.Builder request = createFetchRequest(fetchTarget, data);
……
final RequestFuture<ClientResponse> future = client.send(fetchTarget, request);这里调用client.send进行发送,还是走的ConsumerNetworkClient
Kafka开发案例
import org.apache.kafka.clients.admin.*;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.KafkaFuture;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.time.Duration;
import java.util.*;
import java.util.concurrent.ExecutionException;
public class KafkaExample {
private static final String BOOTSTRAP_SERVERS = "localhost:9092";
private static final String TOPIC_NAME = "test-topic";
public static void main(String[] args) {
// 1. 检查并创建Topic
createTopicIfNotExists(TOPIC_NAME, 3, (short) 1);
// 2. 发送消息
sendMessage(TOPIC_NAME, "key1", "Hello Kafka!");
sendMessage(TOPIC_NAME, "key2", "This is a test message");
// 3. 接收消息
receiveMessages(TOPIC_NAME);
}
/**
* 检查Topic是否存在,不存在则创建
*/
public static void createTopicIfNotExists(String topicName, int partitions, short replicationFactor) {
// 创建Admin客户端配置
Properties adminProps = new Properties();
adminProps.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
try (AdminClient adminClient = AdminClient.create(adminProps)) {
// 检查Topic是否存在
DescribeTopicsResult describeResult = adminClient.describeTopics(Collections.singletonList(topicName));
try {
// 尝试获取Topic描述(如果存在)
describeResult.topicNameValues().get(topicName).get();
System.out.println("Topic \"" + topicName + "\" already exists");
} catch (ExecutionException e) {
if (e.getCause() instanceof org.apache.kafka.common.errors.UnknownTopicException) {
// Topic不存在,创建Topic
System.out.println("Topic \"" + topicName + "\" does not exist. Creating...");
NewTopic newTopic = new NewTopic(topicName, partitions, replicationFactor);
CreateTopicsResult createResult = adminClient.createTopics(Collections.singleton(newTopic));
try {
createResult.all().get();
System.out.println("Topic \"" + topicName + "\" created successfully");
} catch (InterruptedException | ExecutionException ex) {
System.err.println("Failed to create topic: " + ex.getMessage());
}
} else {
System.err.println("Error checking topic existence: " + e.getMessage());
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
System.err.println("Thread interrupted: " + e.getMessage());
}
}
}
/**
* 发送消息到指定Topic
*/
public static void sendMessage(String topicName, String key, String value) {
// 生产者配置
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.ACKS_CONFIG, "all"); // 确保消息完整写入
try (Producer<String, String> producer = new KafkaProducer<>(props)) {
// 创建消息记录
ProducerRecord<String, String> record = new ProducerRecord<>(topicName, key, value);
// 发送消息并获取结果
RecordMetadata metadata = producer.send(record).get();
System.out.printf("Message sent successfully! Topic: %s, Partition: %d, Offset: %d\n",
metadata.topic(), metadata.partition(), metadata.offset());
} catch (InterruptedException | ExecutionException e) {
System.err.println("Error sending message: " + e.getMessage());
}
}
/**
* 从指定Topic接收消息
*/
public static void receiveMessages(String topicName) {
// 消费者配置
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "test-consumer-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); // 从最早的消息开始消费
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // 手动提交offset
try (Consumer<String, String> consumer = new KafkaConsumer<>(props)) {
// 订阅Topic
consumer.subscribe(Collections.singletonList(topicName));
System.out.println("Starting to consume messages from topic: " + topicName);
// 持续消费消息
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
if (records.isEmpty()) {
System.out.println("No more messages. Exiting...");
break;
}
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Received message: key=%s, value=%s, partition=%d, offset=%d\n",
record.key(), record.value(), record.partition(), record.offset());
}
// 手动提交offset
consumer.commitSync();
}
}
}
}
评论区