


符号主义和连接主义之争
符号主义:支持ai应该理解数理逻辑及本质,即不需要刷题就可以会做所有的考试
连接主义:支持ai应该模拟人脑推理、仿生,通过训练达到与人思维一致
机器学习
分类
监督学习:对数据进行100%标注,对数据进行分类
输入:数据集、对应标签
目标:学习映射函数,能够处理输入-输出这种模式
应用:分类、回归,例如房价预测、垃圾邮件分类
半监督学习:对数据进行部分标注和预标注,对少量数据进行分类
输入:大量无标签数据和少量标签数据
目标:利用少量标签数据帮助大量未标注数据学习,从而提高模型准确性
应用:大规模数据集的分类任务,语音识别、图像分类
无监督学习:天然利用数据本身的数理、数学,完全依赖ai自行对数据进行分类
输入:只有输入数据,没有标签
目标:找出隐藏的结构或模式,例如聚类或降维
应用:聚类分析、降维分析、异常检查,例如顾客分群、PCA降维
监督学习
典型算法
线性回归、逻辑回归、决策树、随机森林、最近邻算法、朴素贝叶斯、支持向量机(SVM)、感知器、深度神经网络(DNN)
应用
分类:垃圾邮件检测、情感分析、手写数字识别(MNIST数据集)
回归任务:房价预测、股票市场预测、天气预测
优缺点
优点:训练过程清晰、结果准确
缺点:容易过拟合,且强依赖数据有效性
非监督学习
基本原理
不依赖标注数据,不是预测具体的输出标签,非预测
典型算法
K-means聚类、层次聚类、主成分分析、自编码器、孤立森林
K-means:输入参数有一个比较核心的K值,即找到聚类的中心数,然后计算每个点到中心的均值,即K均值聚类
应用
客户分群、异常检测、数据降维、主题建模
神经网络
感知机模型
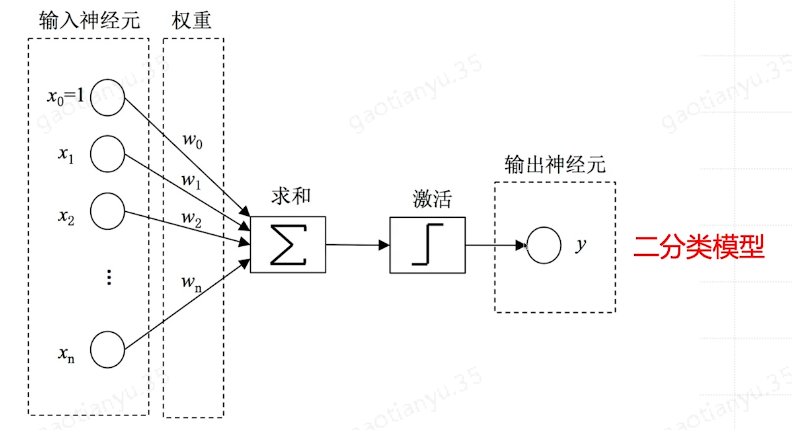
最简单的计算模型
神经网络
在感知机的基础上做进一步升级,即在输入和输出神经元中间加一层隐藏神经元,用于学习和使用复杂函数
深度神经网络就是在中间增加多层隐藏神经元,而每加一层,都极大提升计算量,算力要求极大
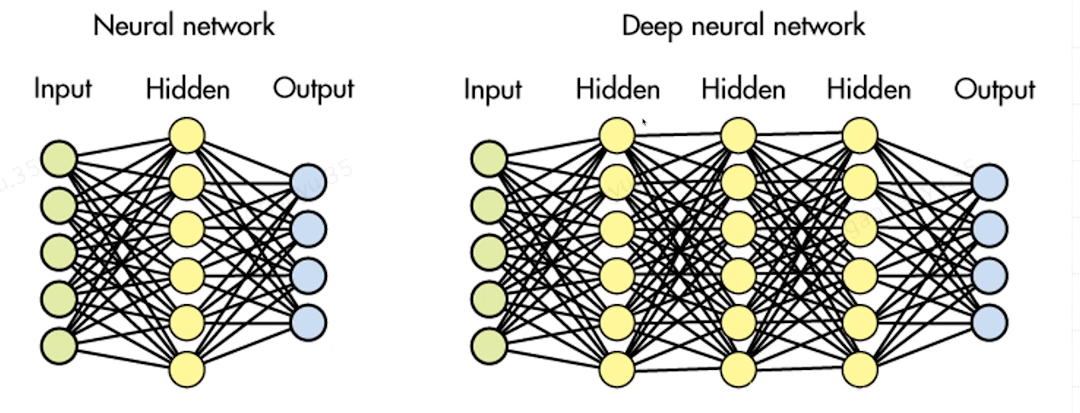
机器学习SVM等算法,需要人工给标注,即专家标注流程;深度学习可以完全解决人工标注这件事情,相比于机器学习,不需要中间人工标注过程介入,提高效率
评论区