


线程与线程池的关系
线程是执行任务的最小单元,单个线程可以启停,从而执行任务。
线程是工厂中的工人, 工人可能自己有设计方法(自己写run方法),也可能使用图纸中的设计方法(任务中的run方法)
任务是工厂承接的设计任务,任务中包括图纸(run方法或call方法)
线程池是工厂,每过来一个任务,工厂就要启动工人生产产品。
工厂为了按图纸生产产品,可以配置启动多少个工人(核心线程数、最大线程数)
工厂接受任务的运营模式是什么(线程池队列)。
可以配置如果任务太多如何决策(抛弃策略)。
线程的基础知识
(1)Thread线程的状态
见源码部分
(2)Thread线程的中断
thread.interrupt()方法只会改变线程的中止状态位,但线程是否立即中止,由线程本身判断。new和terminated对于中断操作几乎是屏蔽的,runnable和blocked类似,对于中断操作只是设置中断标志位并没有强制终止线程,对于线程的终止权利依然在程序手中。waiting/timed_waiting状态下的线程对于中断操作是敏感的,他们会抛出异常并清空中断标志位。
thread.isInterrupted可以判断线程当前标志位是否是中止态
利用isInterrupted和return可以实现判断并彻底中止线程
Thread源码
线程状态综述
线程的内部类Status代表线程状态:
// 刚创建还没开始的状态
NEW
// 就绪状态,可执行,但还没有分配时间片,跟RUNNING区分不明显,都可以叫运行状态
RUNNABLE
// 阻塞状态,进入synchronized关键字修饰的方法或代码块(获取锁)时的状态,一般是由于获取不到锁阻塞
BLOCKED
// 等待状态,执行了wait方法、join方法、AQS的park方法会进入这种状态,无限期等待
WAITING
// 限时等待状态,执行wait(long)、join(long)、AQS的parkNanos、parkUntil会进入这种状态,有限期等待
TIMED_WAITING
// 终止状态,完成任务的状态,不能重新start
TERMINATED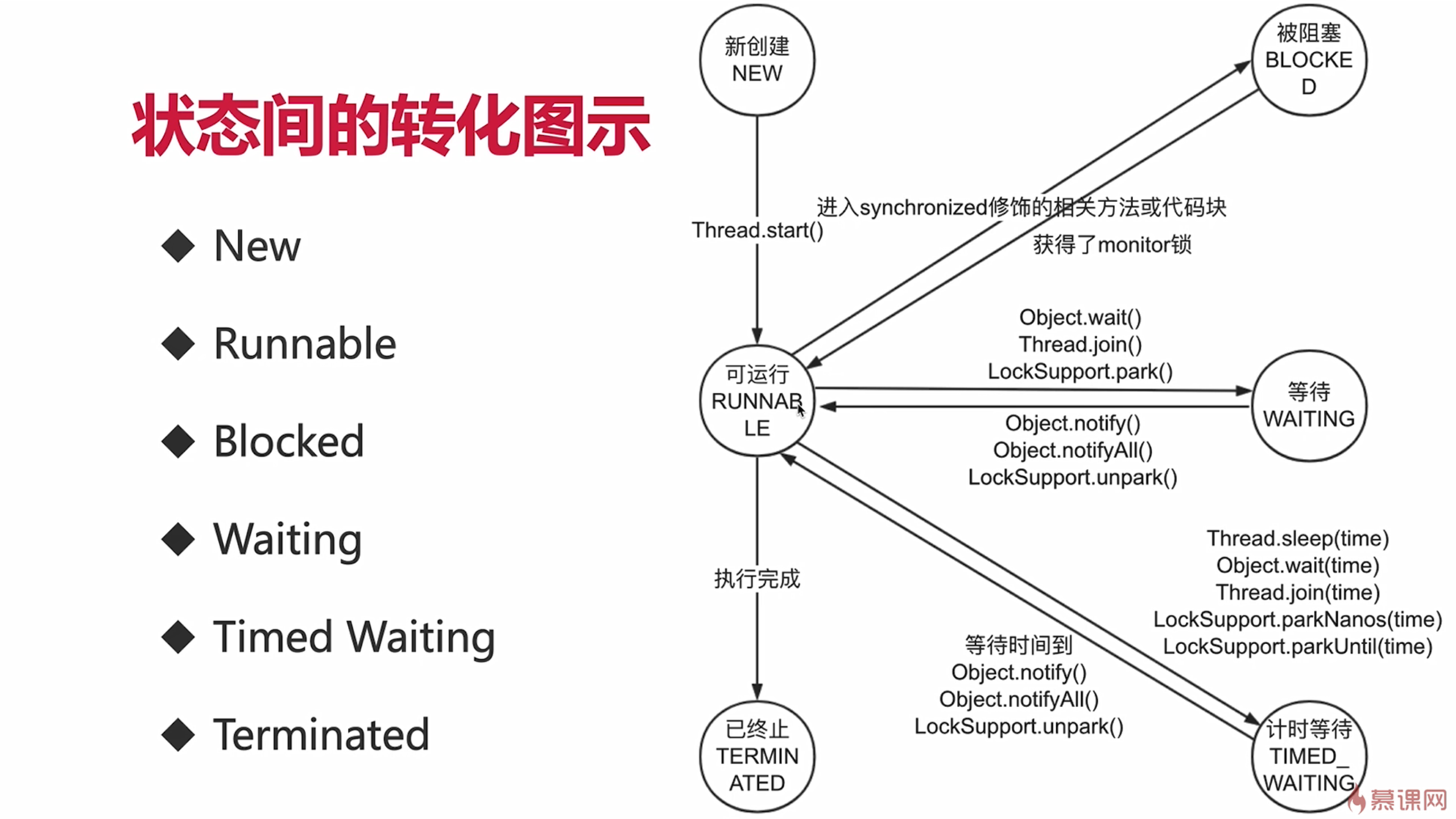
获取线程状态
使用jstack可以获取线程状态
./jstack <pid>WAITING和BLOCKED状态区别
synchronized会导致线程进入Blocked状态,Object.wait()导致线程进入Waiting状态,Waiting线程调用了notify()方法之后,可能会直接获取synchonized锁到达可运行Runnable,但是如果没有获取到synchonized锁的时候应该进入Blocked状态
状态转换常用方法包括:
// sleep:当前线程调用,进入TIMED_WAITING状态,但不释放对象锁,超时后回归RUNNABLE,
// 它是为了给其他线程执行的时机
Thread.sleep(long millies)
// yield:当前线程调用,放弃CPU时间片资源,但不释放对象锁,由RUNNING变为RUNNABLE
// 它是为了给优先级相同的线程被cpu重新选择的机会,但不保证一定轮流执行
Thread.yield()
// join:当前线程调用其他线程t的join方法,当前线程进入WAITING/TIMED_WAITING状态,当前线程不释放对象锁,其他线程t执行完,或到时间回归RUNNABLE状态,也可能因没有synchronized锁进入BLOCKED状态
Thread.join()
// wait:当前线程调用对象的wait方法,当前线程释放对象锁,进入等待队列,依靠notify或wait到时唤醒
Object.wait()
// notify:唤醒此对象监视器上等待的单个线程,选择是任意的,notifyAll唤醒所有线程
Object.notify()
// park:当前线程进入WAITING/TIMED_WAITING状态,对比wait方法不需要获取锁就可以让线程等待,unpark执行唤醒
LockSupport.park()、LockSupport.parkNanos、LockSupport.parkUntil
LockSupport.unpark(Thread thread)RUNNBALE状态
表示线程是可以执行的,就等cpu进行调度了。抢占到cpu时间片资源就可以执行了。有两个子状态:READY就绪和RUNNING运行中就绪到运行是通过cpu调度,而RUNNING到READY是通过Thread.yield()主动释放
核心属性
private Runnable target;
private ThreadGroup group;Thread里面封装了一个Runnable对象target,Thread本身就是一个Runnable对象,为什么还要封装一个Runnable进去,而且在下面构造的时候还要传一个runnable对象进去呢?
这是为了实现执行器和任务的分离。Thread是任务执行的执行器,target是真正的可执行对象,如果二者分离,才能真正实现在线程池流程中thread的复用,如果二者绑定了,那一个任务就绑死在一个线程上了,这个任务执行完成,这个线程就要跟着销毁,不符合线程池和复用的设计理念。
构造方法
Thread的核心成员变量包括:
// 线程名称
private volatile String name;
// 线程上下文
ThreadLocal.ThreadLocalMap threadLocals = null;
// 线程组,存储执行线程
private ThreadGroup group;
// 线程执行的可执行单元(线程执行谁)
private Runnable target;有一个空参构造,一个带参构造,都是最终调用到init方法中。
public Thread() {
init(null, null, "Thread-" + nextThreadNum(), 0);
}
public Thread(Runnable target) {
init(null, target, "Thread-" + nextThreadNum(), 0);
}可以看到二者的区别在于带参构造是传入了一个Runnable可执行单元做target的,这就使得线程和作业分离。
在不指定名称的情况下,线程Thread会自动默认为“Thread-”的名字,如果使用线程工厂,就可以自己指定名称。
init方法
// 设置当前线程是该线程的父线程
Thread parent = currentThread();
……
// 向threadGroup中添加未执行线程
g.addUnstarted();
this.group = g;
// 将daemon、priority属性设置为父线程的对应属性,这里daemon就是是否是守护线程
this.daemon = parent.isDaemon();
this.priority = parent.getPriority();
……
// 传入核心变量target,后面run的时候使用,target代表的就是线程要执行的runnable对象
this.target = target;
……
// 将父类的可继承inheritThreadLocal继承过来
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
// 分配线程id
tid = nextThreadID();start - java多线程启动入口
Thread提供了start方法,是java多线程启动的入口。
if (threadStatus != 0)
throw new IllegalThreadStateException();首先判断status,0代表NEW状态,如果不是new状态,不允许thread执行start方法。
start0();
started = true;最核心的在这里,执行start0方法。start0是一个native方法,它的实现包括:
首先,它会检查当前线程对象的状态是否允许启动。如果线程对象的状态不满足启动条件,start0()方法将抛出一个IllegalThreadStateException异常。
接下来,start0()方法会为新线程分配所需的系统资源和内存空间。这包括为线程创建一个独立的执行环境和堆栈空间。
一旦系统资源和内存分配完成,start0()方法将调用操作系统提供的原生函数,以便创建一个真正的操作系统级线程。这个原生函数可能是基于平台的API,比如Windows的CreateThread()或Linux的pthread_create()。
最后,start0()方法会更新线程对象的状态,并且将线程添加到线程调度器中,使其可以被调度执行。
同时,在start0的执行过程中,JVM会自动调用线程thread的run方法。因此在jdk源码中,实际看不到run方法的调用,但其实在start方法触发时就执行了run方法。
run - 线程执行单元
集成Runnable接口的Thread类实现了Runnable的run方法。这里思考,为什么不是Thread直接自带run方法?
这样可以实现线程和可执行单元的分离。如果线程自带run,那么创建多个可执行任务就是多个thread,只能一个执行一个,而通过创建一个Runnable,可以给多个线程执行,对一个Runnable进行并发处理。例如银行取号机,四台取号机共用一天的1-50号码序列,要对一个可执行单元做并发。
Thread实现的run方法实际就比较简单了:
public void run() {
if (target != null) {
target.run();
}
}相当于它将执行内容直接交给了可执行单元去实现。这就是典型的策略模式,执行器和可执行单元分离。
线程死锁
死锁的概念
死锁是指两个线程同时拥有对方请求的资源,导致均永远无法执行下去。
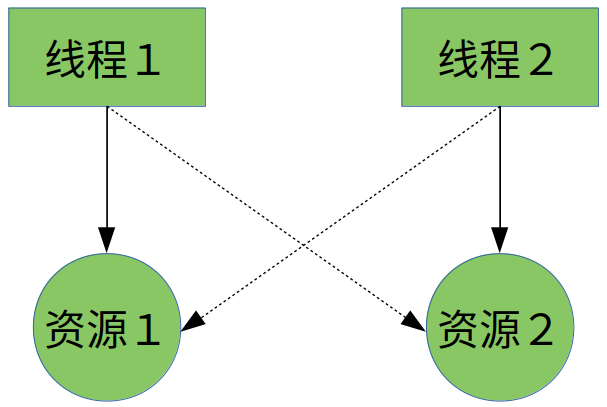
Object lockA = new Object();
synchronized (lockA) {
System.out.println("线程 1:获取到锁 A!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程 1:等待获取 B...");
synchronized (lockB) {
System.out.println("线程 1:获取到锁 B!");
}
}synchronized (资源) {}中的代码段在执行时保有对资源的占用,其他线程想要使用资源A必须先请求锁。
解决死锁的方法
顺序锁
将线程对资源的请求由互斥改为顺序,如下图:
加图
锁超时
Lock lockA = new ReentrantLock();
Lock lockB = new ReentrantLock();
public static void pollingLock(Lock lockA, Lock lockB) {
while (true) {
if (lockA.tryLock()) { // 尝试获取锁
System.out.println("线程 1:获取到锁 A!");
try {
Thread.sleep(1000);
System.out.println("线程 1:等待获取 B...");
if (lockB.tryLock()) { // 尝试获取锁
try {
System.out.println("线程 1:获取到锁 B!");
} finally {
lockB.unlock(); // 释放锁
System.out.println("线程 1:释放锁 B.");
break;
}
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lockA.unlock(); // 释放锁
System.out.println("线程 1:释放锁 A.");
}
}
// 等待一秒再继续执行
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}上示例lockB.tryLock()获取不到会报中断异常,释放锁A,然后执行try语句等待1秒,再重新while true循环
Runnable和Callable
实现Runnable接口/Callable接口表明此对象是一个可执行任务
二者的区别在于:
run()实现自runnable接口,call()实现自callable接口
callable 和runnable 很像, callable 的call() 方法可以等同于runnable 的run() 方法,
call() 能返回结果,run() 不能。
call() 可以抛出受检查的异常,比如ClassNotFoundException, 而run()不能抛出受检查的异常。
评论区