


本篇以一个最基础的问题作为主线:如何实现一个最简单的spring-bean?
通过Class+xml配置文件就可以做到:
// BeanClass
public class MyTestBean {
private String testStr = "testStr";
public String getTestStr() {
return testStr;
}
public void setTestStr(String testStr) {
this.testStr = testStr;
}
}<!-- spring-beans.xml -->
<?xml version = "1.0" encoding = "UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http">
<bean id="myTestBean" class="test.MyTestBean"/>
</beans>现在我们可以加一个main方法,用于获取这个bean:
// 启动类 - 完成spring从xml读取bean的配置
public class MyTest {
@SuppressWarnings("deprecation")
@Test
public void testSimpleLoad() {
BeanFactory bf = new XmlBeanFactory(new ClassPathResource("spring-beans.xml"));
MyTestBean bean = (MyTestBean) bf.getBean("myTestBean");
System.out.println(bean.getTestStr());
}
}可以看到,只使用了一个最简单的方法new XmlBeanFactory(new ClassPathResource("spring-beans.xml")),我们就获取了一个BeanFactory,并且从这个BeanFactory中取出了我们想要的bean
那么问题来了:
1、xml是如何被加载成BeanFactory的?
2、BeanFactory是如何取出我想要的Bean的
本篇先分析第二个问题:beanFactory是如何取出我想要的bean的
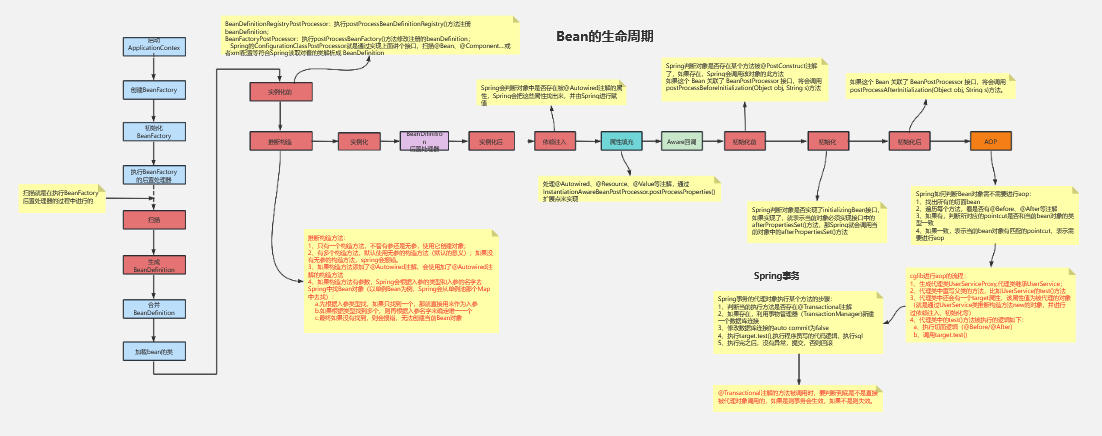
bean的生命周期解析
bean的生命周期概括
spring中bean的生命周期包括实例化、设置属性、初始化、使用bean、销毁bean
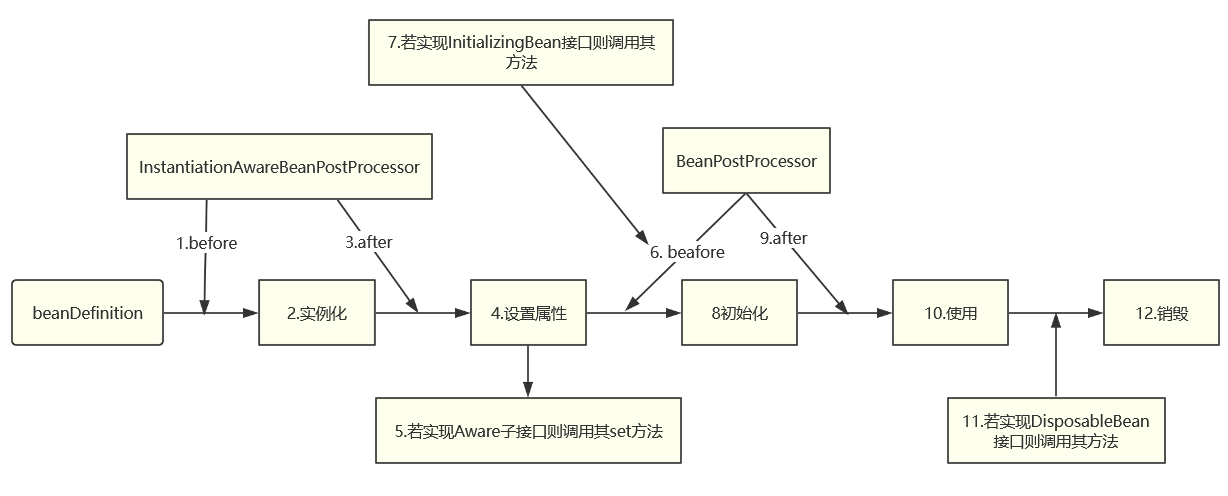
在bean的生命周期过程中有很多可选的插入式前置/后置处理器,例如:
实例化:给Bean分配内存空间(对应JVM中的“加载”,这里只是分配了内存)
设置属性:进行Bean的注入和装配
初始化
执行各种通知
执行初始化的前置工作
进行初始化工作(使用注解 @PostConstruct 初始化 或者 使用(xml)init-method 初始化, 前者技术比后者技术先进~)
执行初始化的后置工作
实例化和初始化是两个完全不同的过程,前者只是给Bean分配内存空间,而后者则是将程序执行权从系统级别转到用户级别,执行用户添加的业务代码
初始化bean的时序图可以参考:
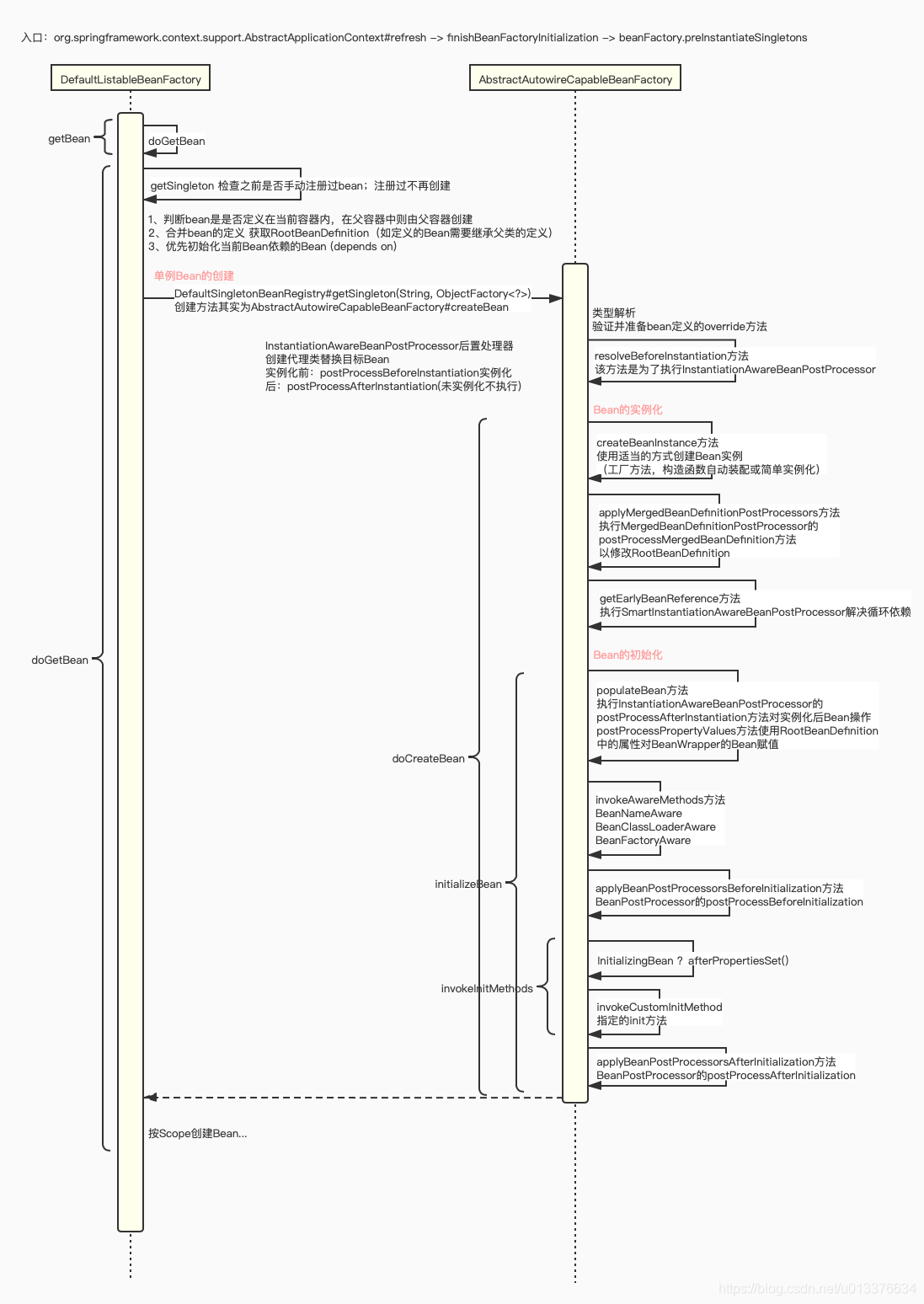
bean获取相关类
根据上面的案例,获取bean是通过getBean方法触发的:
MyTestBean bean = (MyTestBean) bf.getBean("myTestBean");DefaultListableBeanFactory
在xml加载的流程中我们见到过它
在xml解析的流程中,它提供的能力是:
注册beanDefinitionL:
DefaultListableBeanFactory#registerBeanDefinition获取beanDefinition:
DefaultListableBeanFactory#getBeanDefinition
一个注册完的beanDefinition会存储在beanDefinitionNames和beanDefinitionMap中,见下面核心成员变量:
核心成员变量
// beanDefinition的内存缓存,注册好的bd会在这里存储,key是beanName
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);
// bdName,按注册顺序排序,注册中的bean会先到这里
private volatile List<String> beanDefinitionNames = new ArrayList<>(256);
// 正在走create流程的bean
private final Set<String> singletonsCurrentlyInCreation = Collections.newSetFromMap(new ConcurrentHashMap<>(16));
// 三级缓存=成品bean缓存:beanName对应加载好的bean实例的缓存
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 三级缓存=半成品bean缓存:beanName对应实例化但没有初始化的bean实例的缓存,没有注入
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
// 三级缓存=beanFactory缓存:beanName对应的暴露的工厂
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
// FactoryBean的产物缓存
private final Map<String, Object> factoryBeanObjectCache = new ConcurrentHashMap<>(16);getBean(String name)
根据beanName获取bean,继承自AbstractBeanFactory
public Object getBean(String name) throws BeansException {
return doGetBean(name, null, null, false);
}doGetBean
同样继承自AbstractBeanFactory
doGetBean方法正式进入了bean的获取和使用流程。在期间,bean完成了加载。doGetBean是提供给外部用于获取bean的方法,ApplicationContext中的getBean内部调用的就是doGetBean方法。
方法整体架构较为复杂,大致分为九个步骤:
步骤一、处理并获取beanName
String beanName = transformedBeanName(name);首先要处理beanName,该方法调用了canonicalName方法,继承自SimpleAliasRegistry,是用于处理别名的,在xml解析的流程中也见到过它,它将别名处理完后,存放在aliasMap中,参考下面链接:
protected String transformedBeanName(String name) {
return canonicalName(BeanFactoryUtils.transformedBeanName(name));
}public String canonicalName(String name) {
String canonicalName = name;
// Handle aliasing...
String resolvedName;
do {
resolvedName = this.aliasMap.get(canonicalName);
if (resolvedName != null) {
canonicalName = resolvedName;
}
}
while (resolvedName != null);
return canonicalName;
}可以看到这里的主要目的是为了检查一下传进来的name是不是别名,如果在别名map中可以找到对应的beanid,则返回真实beanId后续用beanId去处理。
步骤二、根据beanName获取单例
Object sharedInstance = getSingleton(beanName);在getSingleton方法中,spring尝试从缓存中加载,分别查看了singletonObjects(初始化完成的bean)、earlySingletonObjects(已经实例化但未初始化未填充属性的bean)、singletonFactories(bean的FactoryBean缓存)三个缓存,基本思路为:
singletonObjects中存在,返回singleObject对象;不存在,在earlySingletonObjects中找
earlySingletonObjects中存在,返回singleObject对象;不存在,在singletonFactories中找
从singletonFactories能找到对应的工厂实例ObjectFactory,调用getObject方法获取singleObject对象,找不到对应的ObjectFactory,返回null,同时在earlySingletonObjects中存beanName对应null,在singletonObjects中移除beanName
这就是spring解决循环依赖的三级缓存,代码如下:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 现在singletonObject缓存中找看看有没有已经加载完成的单例
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 没有加载好的,再取earlySingletonObjects中找已经实例化但是还没有初始化的bean
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 都没有,说明bean还没有实例化,这里做dcl单例,加锁,再判断一轮,如果是正在实例化,这里拿不到锁
synchronized (this.singletonObjects) {
// 拿到锁后再判断一圈,如果还没有,就说明bean真没实例化了
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// singletonFactories中找bean的FactoryBean缓存
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 如果发现工厂bean已经有了,直接调用getObject方法开始加载bean就可以了
// 如果工厂bean都还没暴露,就要重头开始初始化工厂bean了
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}这里要区分一个概念:ObjectFactory和BeanFactory
BeanFactory是承载所有Bean加载方法的类,是bean的生产车间,默认实现就是DefaultListableBeanFactory
ObjectFactory是bean的模具,每个bean一定有一个ObjectFactory与之对应,其核心方法
ObjectFactory#getObject,实现该方法就让ObjectFactory创建某种bean的能力,即实例化、填充、初始化的全流程
话说回来,在DefaultSingletonBeanRegistry#getSingleton 方法中调用ObjectFactory#getObject 方法,拿到了一个Object,如果获取到了,这里其实就是把bean初始化好了这里需要注意的是,获取到的bean不是最终的bean,因为有FactoryBean工厂bean存在,因此走步骤三完成最终装配
如果这里拿到的是null,或者FactoryBean的实例就是null那肯定执行不了ObjectFactory#getObject方法,bean也就连实例化都没完成,因此走步骤四-九,从头开始创建bean
步骤三、最终装配
// 条件1:有实例化的结果,且bean是用的无参构造
if (sharedInstance != null && args == null) {
if (logger.isTraceEnabled()) {
// 条件2:判断是否在singletonsCurrentlyInCreation缓存中,表示bean已经在create了
if (isSingletonCurrentlyInCreation(beanName)) {
logger.trace……;
}
else {
logger.trace……;
}
}
// 最终装配
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}首先看条件1,如果bean是无参构造的,且已经能找到创建好的bean了
判断条件2不是正在加载中,如果是的话,就不处理了,防止并发,如果不是,说明确实已经加载好了,然后获取真正的bean
什么叫获取真正的bean?这里是因为引入了FactoryBean的概念,可以参考getObjectForBeanInstance方法
步骤四、原型模式依赖检查
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);如果步骤二获取不到实例,进行原型模式依赖检查。
只有在单例情况下才会尝试解决循环依赖,BeanFactory 不缓存 Prototype 类型的 bean,无法处理该类型 bean 的循环依赖问题,也就是情况:AbstractBeanFactory#isPrototypeCurrentlyInCreation判断true
步骤五、通过父容器查找bean
对于步骤二根据beanName在缓存中获取不到实例的,且通过步骤四循环调用检查的,则到父容器中查找 bean
// Check if bean definition exists in this factory.
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
// Not found -> check parent.
String nameToLookup = originalBeanName(name);
if (parentBeanFactory instanceof AbstractBeanFactory) {
return ((AbstractBeanFactory) parentBeanFactory).doGetBean(
nameToLookup, requiredType, args, typeCheckOnly);
}
else if (args != null) {
// Delegation to parent with explicit args.
return (T) parentBeanFactory.getBean(nameToLookup, args);
}
else if (requiredType != null) {
// No args -> delegate to standard getBean method.
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
else {
return (T) parentBeanFactory.getBean(nameToLookup);
}
}委托父类工厂加载的两个条件:
父类工厂方法非null
!containsBeanDefinition(beanName)是在检测如果当前加载的XML配置⽂件中不包含beanName所对应的配置,就只能到parentBeanFactory去尝试下了
最后再去递归的调⽤getBean⽅法
步骤六、将xml解析的GenericBeanDefinition转换为RootBeanDefinition
RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
checkMergedBeanDefinition(mbd, beanName, args);因为从XML配置⽂件中读取到的bean信息是存储在GernericBeanDefinition中的,但是所有的bean后续处理都是针对于RootBeanDefinition的,所以这⾥需要进⾏⼀个转换,转换的同时如果⽗类bean不为空的话,则会⼀并合并⽗类的属性。
步骤七、寻找依赖并优先进行依赖bean的实例化
bean初始化时某些属性可能是动态配置且依赖其他bean,因此初始化bean之前,先要初始化这个bean的依赖。要注意的是,这里提前解析的是depends-on属性,而非@Autowired或其他属性注入方式注入的依赖,因此这里如果循环依赖了,那就是死循环了
// Guarantee initialization of beans that the current bean depends on.
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
for (String dep : dependsOn) {
// 先处理depends-on属性循环
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
// 缓存依赖调用
registerDependentBean(dep, beanName);
try {
// 递归getBean方法进行依赖bean的实例化
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"'" + beanName + "' depends on missing bean '" + dep + "'", ex);
}
}
}首先mbd.getDependsOn()获取到所有的依赖bean,这里是通过BeanDefinition的dependsOn属性取的,实际上是处理以下这种场景:
<bean id="beanA" class="BeanA" depends-on="beanB">depends-on属性的解析可以参考以下链接:
然后分别调用DefaultSingletonBeanRegistry#registerDependentBean和AbstractBeanFactory#getBean方法把依赖bean注册了并实例化了,这里都还好理解
上面还有一个isDependent方法,它判断的实际上是严格依赖的depends-on属性,例如:
<bean id="beanA" class="BeanA" depends-on="beanB">
<bean id="beanB" class="BeanB" depends-on="beanA">这种会直接判断抛异常
private boolean isDependent(String beanName, String dependentBeanName, @Nullable Set<String> alreadySeen) {
……
Set<String> dependentBeans = this.dependentBeanMap.get(canonicalName);
……
if (dependentBeans.contains(dependentBeanName)) {
return true;
}
……
for (String transitiveDependency : dependentBeans) {
if (isDependent(transitiveDependency, dependentBeanName, alreadySeen)) {
return true;
}
}
return false;
}但是这个isDependent方法看起来判true的思路有点难懂,这里要结合下面DefaultSingletonBeanRegistry#registerDependentBean 方法一起看,就明白了
public void registerDependentBean(String beanName, String dependentBeanName) {
String canonicalName = canonicalName(beanName);
synchronized (this.dependentBeanMap) {
Set<String> dependentBeans =
this.dependentBeanMap.computeIfAbsent(canonicalName, k -> new LinkedHashSet<>(8));
if (!dependentBeans.add(dependentBeanName)) {
return;
}
}
synchronized (this.dependenciesForBeanMap) {
Set<String> dependenciesForBean =
this.dependenciesForBeanMap.computeIfAbsent(dependentBeanName, k -> new LinkedHashSet<>(8));
dependenciesForBean.add(canonicalName);
}
}首先注册beanA的时候,isDependent判断是不会抛异常的,走到registerDependentBean方法,这里主要是注册了两个map:
dependentBeansMap:beanA对应的依赖bean的集合
dependeciesForBeanMap:beanB对应的依赖它的集合
这样在实例化beanB的时候,再次走到isDependent方法就会发现自己在被依赖的bean列表中
步骤八、针对不同的scope进行bean创建
默认的scope是单例singleton,还有其他配置例如prototype、request等,对应不同的初始化策略
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
……
}
});
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
else if (mbd.isPrototype()) {
// It's a prototype -> create a new instance.
Object prototypeInstance = null;
try {
beforePrototypeCreation(beanName);
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
beanInstance = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);
}
else {
……
}可以看到三个条件分成三个场景:
singleton场景
prototype场景
非singleton和prototype场景、自定义场景等
主要看下前两个场景:
singleton场景
singleton场景主要是调用了两个方法:
sharedInstance = getSingleton(beanName, ……)
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);而getSingleton里面一大坨实际上是一个ObjectFactory#getObject的匿名实现,里面实际调用的是AbstractBeanFactory#createBean 方法
() -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
……
}
}这么看实际上是三个方法共同作用的结果:
getSingleton:是前面那个getSingleton方法的多态版本,获取bean实例的框架方法,承担的作用包括实例化bean、完成一些三级缓存的判断和配置工作,如果bean是非FactoryBean,这里拿到就是bean本身,如果是FactoryBean,拿到的就是FactoryBean的bean本身,还要在后面额外获取到工厂产物
匿名方法:不涉及三级缓存的判断和配置,真正的实例化方法是createBean方法
getObjectForBeanInstance:一个获取真正bean的方法,其实前面的getSingleton方法中就已经见过了,点我跳转
prototype场景
prototype场景因为不存在循环依赖那些问题,就不需要搞一堆缓存的框架了,直接调用AbstractBeanFactory#createBean
同时前后各调用了一个AbstractBeanFactory#beforePrototypeCreation 和AbstractBeanFactory#afterPrototypeCreation 主要是登记了一个为了防止并发实例化bean的缓存
try {
beforePrototypeCreation(beanName);
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
beanInstance = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);最后再取出真正的bean实例,与singleton方法大致是一致的
步骤九、类型转换
doGetBean方法的最后一步
return adaptBeanInstance(name, beanInstance, requiredType);获取bean已经基本结束了。但可能bean有requiredType,返回的bean是string,但requiredType是Integer,那么就需要这一步骤进行类型转换。用户也可以自定义转换器。
核心代码就是一步判断和一步调用:
if (requiredType != null && !requiredType.isInstance(bean)) {
try {
Object convertedBean = getTypeConverter().convertIfNecessary(bean, requiredType);
if (convertedBean == null) {
throw new BeanNotOfRequiredTypeException(name, requiredType, bean.getClass());
}
return (T) convertedBean;
}可以继续了解TypeConverter#convertIfNecessary ,点我跳转
createBean
继承自AbstractAutowireCapableBeanFactory,这个类顾名思义,具有自动注入能力的beanFactory
方法分为四个步骤:
步骤一、加载bean对应的class
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}首先锁定class,然后根据设置的class属性或者根据className来解析Class。这里是为了预先判断bean对应的class有没有被解析过
if (System.getSecurityManager() != null) {
return AccessController.doPrivileged((PrivilegedExceptionAction<Class<?>>)
() -> doResolveBeanClass(mbd, typesToMatch), getAccessControlContext());
}
else {
return doResolveBeanClass(mbd, typesToMatch);
}doResolveBeanClass方法中提供了多种加载类的方法,包括直接实现ClassLoader的,以及调用spring自己的Class工具类的
步骤二、处理override方法
try {
mbdToUse.prepareMethodOverrides();
}这里只是统计override方法数量,如果当前类的方法只有一个,那么就设置该重载方法没有被重载,后续就不需要进行方法的参数匹配验证了
步骤三、实例化的前置处理和短路操作
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}resolveBeforeInstantiation方法是对BeanDefinition中的属性做前置处理的。当经过前置处理后返回的结果如果不为空,那么会直接短路,略过后续的bean的创建⽽直接返回结果。这⼀特性虽然很容易被忽略,但是却起着⾄关重要的作⽤,我们熟知的AOP功能就是基于这⾥的判断的。
protected Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd) {
Object bean = null;
if (!Boolean.FALSE.equals(mbd.beforeInstantiationResolved)) {
// Make sure bean class is actually resolved at this point.
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
Class<?> targetType = determineTargetType(beanName, mbd);
if (targetType != null) {
// 实例化前置处理
bean = applyBeanPostProcessorsBeforeInstantiation(targetType, beanName);
if (bean != null) {
// 初始化后置处理
bean = applyBeanPostProcessorsAfterInitialization(bean, beanName);
}
}
}
mbd.beforeInstantiationResolved = (bean != null);
}
return bean;
}在方法内分别调用了前处理和后处理两个方法:applyBeanPostProcessorsBeforeInstantiation、applyBeanPostProcessorsAfterInitialization
其他前/后置处理器可以参考:
其中,前处理发生在AbstractBeanDefinition转换为BeanWrapper前,给子类修改BeanDefinition的机会。这里可能bean就已经不是原本的bean了,可能成为了一个经过处理的代理bean。可能是通过cglib生成的。
后处理方法返回的bean如果不为空,后续就不再进行普通bean的创建过程。也避免单例循环创建,也可以在A与B互相依赖,创建A后又创建B又要创建A的时候直接获取到,避免循环依赖。
步骤四、加载bean
步骤三之后还获取不到真正的bean,执行真正的加载操作。
Object beanInstance = doCreateBean(beanName, mbdToUse, args);doCreateBean - 初始化bean的核心
doCreateBean方法是初始化bean的核心方法,整个方法可以看作三个大步骤:
实例化
属性注入
初始化
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
……
// 实例化
instanceWrapper = createBeanInstance(beanName, mbd, args);
……
// 属性注入
populateBean(beanName, mbd, instanceWrapper);
// 初始化
exposedObject = initializeBean(beanName, exposedObject, mbd);
……
}
步骤一、实例化
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}首先判断是不是单例,如果是单例,从缓存factoryBeanInstanceCache中获取并移除缓存
如果不是单例,或缓存里面没有,直接调用createBeanInstance方法构建
try {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}然后应用MergedBeanDefinitionPostProcessor这个BD合并后置处理器
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}实例化之后判断是否需要暴露早期bean工厂,从而解决循环依赖问题
工厂是一个匿名类,实现了ObjectFactory#getObject方法,它实现的方式并不是像默认工厂DefaultListableBeanFactory那样走全流程,而是简单的获取bean早期实例,即没有属性注入没有初始化的bean
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}其中调用的方法是AbstractAutoProxyCreator#getEarlyBeanReference ,点我跳转
再看addSingletonFactory
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}就是对三级缓存相关的三个核心成员变量的操作了
步骤二、属性注入
populateBean(beanName, mbd, instanceWrapper);直接参考populateBean部分
步骤三、初始化
exposedObject = initializeBean(beanName, exposedObject, mbd);直接参考initializeBean部分
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
……然后后面是一部分缓存处理,用于处理循环依赖,如果有循环依赖,这里earlySingletonReference != null才成立,才处理内部逻辑
try {
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch ……
}
return exposedObject;最后注册到 disposableBeans 里面,以便在销毁bean 的时候 可以运行指定的相关业务,然后返回初始化完成的bean
createBeanInstance - 实例化并解决三级循环依赖
Class<?> beanClass = resolveBeanClass(mbd, beanName);解析bean class,这个事情正常前面已经做过了
构建bean实例的方法有三种:supplier接口、工厂方法、构造函数
supplier接口流程
Supplier<?> instanceSupplier = mbd.getInstanceSupplier();
if (instanceSupplier != null) {
return obtainFromSupplier(instanceSupplier, beanName);
}protected BeanWrapper obtainFromSupplier(Supplier<?> instanceSupplier, String beanName) {
……
try {
instance = instanceSupplier.get();
}
……
BeanWrapper bw = new BeanWrapperImpl(instance);
initBeanWrapper(bw);
return bw;
}这里大致可以看出来,是从BeanDefinition里面解析出来的supplier接口,调用Supplier#get方法
这里解析supplier接口使用了一个initBeanWrapper方法
工厂方法流程
if (mbd.getFactoryMethodName() != null) {
return instantiateUsingFactoryMethod(beanName, mbd, args);
}protected BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
return new ConstructorResolver(this).instantiateUsingFactoryMethod(beanName, mbd, explicitArgs);
}首先调用ConstructorResolver#instantiateUsingFactoryMethod方法创建工厂,点我跳转
bw.setBeanInstance(instantiate(beanName, mbd, factoryBean, factoryMethodToUse, argsToUse));从这一块就可以看出来,找了FactoryBean、找了FactoryMethod、找了参数argsToUse
然后在instantiate方法里面调用了SimpleInstantiationStrategy#instantiate 点我跳转
return this.beanFactory.getInstantiationStrategy().instantiate(
mbd, beanName, this.beanFactory, factoryBean, factoryMethod, args);解析构造函数流程
boolean resolved = false;
boolean autowireNecessary = false;
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
if (mbd.resolvedConstructorOrFactoryMethod != null) {
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}如果已经解析好了,且需要自动装配,走自动装配流程,不需要的话走默认无参构造函数构造
if (resolved) {
if (autowireNecessary) {
// 自动装配流程
return autowireConstructor(beanName, mbd, null, null);
}
else {
// 无参构造流程
return instantiateBean(beanName, mbd);
}
}自动装配流程参考autowireConstructor方法,
instantiateBean和之前一样调用到SimpleInstantiationStrategy#instantiate方法,点我跳转,然后再调用initBeanWrapper初始化beanWrapper,点我跳转,和上面supplier接口方法流程基本一致
Object beanInstance = getInstantiationStrategy().instantiate(mbd, beanName, this);
BeanWrapper bw = new BeanWrapperImpl(beanInstance);
initBeanWrapper(bw);到这里实例化方法createBeanInstance的流程框架就结束了,点我返回doCreateBean
populateBean
继承自AbstractAutowireCapableBeanFactory,负责处理属性注入
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {
if (!bp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
return;
}
}
}这是bean属性设置前最后一次切入改变bean的机会,通过实现后处理器BeanPostProcessor#postProcessAfterInstantiation方法处理。
这里不做拦截,就往后做属性注入了
// 第一种注入模式:xml autowire属性自动注入
int resolvedAutowireMode = mbd.getResolvedAutowireMode();
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// Add property values based on autowire by name if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// Add property values based on autowire by type if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}然后就到了最重要的注入部分,第一种注入模式是根据xml中的autowire属性自动注入,例如:
<bean id="user" class="com.yth.service.User" autowire="byName"/>如果没有指定这个属性,而是写了@Autowired注解,则这时候拿到的propertyValue还是null,继续往后
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {
PropertyValues pvsToUse = bp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
……这里又一次找到了BeanPostProcessor,通过BeanPostProcessor#postProcessProperties引入一些自定义的属性处理机制(个人开发者实现这个方法的较少),例如注解扫描器就是在这里引入的,对应的实现是AutowiredAnnotationBeanPostProcessor
找完对应的bean后到了真正的填充属性流程,参考applyPropertyValues
if (pvs != null) {
applyPropertyValues(beanName, mbd, bw, pvs);
}initializeBean - 初始化bean
分别通过aware方法初始化,和用户自定义的initMethod初始化。
首先是对特殊的bean进行处理:实现了Aware、BeanClassLoaderAware、BeanFactoryAware的处理。参考invokeAwareMethods方法
invokeAwareMethods(beanName, bean);然后调用BeanPostProcessor#postProcessBeforeInitialization方法做初始化前置处理,这个时候是已经完成了bean的实例化(createBeanInstance)和属性填充(populateBean)工作
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
// ---------AbstractAutowireCapableBeanFactory#applyBeanPostProcessorsBeforeInitialization---------
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessBeforeInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}激活自定义的init方法,见invokeInitMethods方法
try {
invokeInitMethods(beanName, wrappedBean, mbd);
}最后调用BeanPostProcessor#postProcessAfterInitialization做初始化后置处理,这时候bean已经实例化完成了
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
// ----------AbstractAutowireCapableBeanFactory#applyBeanPostProcessorsAfterInitialization--------------------
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}如果是AOP场景,初始化完成的后处理器中就会有AOP创建相关的,见AOP部分
getObjectForBeanInstance - 获取真正的bean
继承自AbstractBeanFactory#getObjectForBeanInstance
首先引入一个概念:FactoryBean
FactoryBean也是一个bean,因此也是通过spring这套逻辑加载的,但是它有个特殊点就是它是一个Factory,可以理解为它是bean的模具,专门用于生产一些特殊的不方便直接定义的bean
它有一个专门的“生产”方法:
T getObject() throws Exception;这个getObject()方法的作用是,它让FactoryBean的create流程实际上调用的是FactoryBean#getObject方法,即bean定义的是FactoryBean,但加载出来实际上是FactoryBean的产物
FactoryBean的作用主要是为了丰富bean的创建方式,生产一些特殊的不方便直接定义的bean
回来看getObjectForBeanInstance方法:
if (BeanFactoryUtils.isFactoryDereference(name)) {
if (beanInstance instanceof NullBean) {
return beanInstance;
}
if (!(beanInstance instanceof FactoryBean)) {
throw new BeanIsNotAFactoryException(beanName, beanInstance.getClass());
}
if (mbd != null) {
mbd.isFactoryBean = true;
}
return beanInstance;
}首先判断beanName是以“&”开头的,这里的意义是,如果我就是想取出FactoryBean本身实例而非FactoryBean的产物,定义bean的时候就要让beanName以&开头
如果name不以&开头,且不说FactoryBean,则直接返回本身
if (!(beanInstance instanceof FactoryBean)) {
return beanInstance;
}如果是FactoryBean,则调用FactoryBeanRegistrySupport#getCachedObjectForFactoryBean 获取产物
else {
object = getCachedObjectForFactoryBean(beanName);
}
if (object == null) {
……
object = getObjectFromFactoryBean(factory, beanName, !synthetic);
}可以看到,也是先从缓存中取,缓存中没有,则从头走创建流程,调用getObjectFromFactoryBean
这里的缓存是factoryBeanObjectCache,可以参考前面核心成员变量部分
PS:Mybatis中的SqlSessionFactoryBean就是一个很典型的FactoryBean的案例,它的作用是将DAO层的xml文件(sql文件)加载成bean,参考下面连接:
getObjectFromFactoryBean
继承自FactoryBeanRegistrySupport#getObjectFromFactoryBean
synchronized (getSingletonMutex()) {
Object object = this.factoryBeanObjectCache.get(beanName);
if (object == null) {
object = doGetObjectFromFactoryBean(factory, beanName);
……
……
object = postProcessObjectFromFactoryBean(object, beanName);首先加同步锁,加锁对象是前面看到的成品bean缓存
public final Object getSingletonMutex() {
return this.singletonObjects;
}然后做double check,如果还是null,调用doGetObjectFromFactoryBean
后面调用一个插入式的后处理器postProcessObjectFromFactoryBean
这个方法在AbstractAutowireCapableBeanFactory#postProcessObjectFromFactoryBean中重写了一下,引入了后置处理器BeanPostProcessor
protected Object postProcessObjectFromFactoryBean(Object object, String beanName) {
return applyBeanPostProcessorsAfterInitialization(object, beanName);
}后置处理器可以参考链接:
doGetObjectFromFactoryBean
核心代码其实就一处:
object = factory.getObject();调用FactoryBean#getObject
autowireByName、autowireByType
autowireByName比较简单,按name找bean
String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);protected String[] unsatisfiedNonSimpleProperties(AbstractBeanDefinition mbd, BeanWrapper bw) {
Set<String> result = new TreeSet<>();
PropertyValues pvs = mbd.getPropertyValues();
PropertyDescriptor[] pds = bw.getPropertyDescriptors();
for (PropertyDescriptor pd : pds) {
if (pd.getWriteMethod() != null && !isExcludedFromDependencyCheck(pd) && !pvs.contains(pd.getName()) &&
!BeanUtils.isSimpleProperty(pd.getPropertyType())) {
result.add(pd.getName());
}
}
return StringUtils.toStringArray(result);
}这里调用了AbstractAutowireCapableBeanFactory#unsatisfiedNonSimpleProperties 方法,看其逻辑,可知是为了从BD中拿到所有的属性名称
for (String propertyName : propertyNames) {
if (containsBean(propertyName)) {
Object bean = getBean(propertyName);
pvs.add(propertyName, bean);
registerDependentBean(propertyName, beanName);
……然后对于这个名称数组,遍历完成依赖bean的加载,这时候要调getBean方法,这里就有可能产生循环依赖
autowireByType与autowireByName比较类似,只是多了一步根据type解析依赖的流程
for (String propertyName : propertyNames) {
try {
PropertyDescriptor pd = bw.getPropertyDescriptor(propertyName);
// Don't try autowiring by type for type Object: never makes sense,
// even if it technically is an unsatisfied, non-simple property.
if (Object.class != pd.getPropertyType()) {
MethodParameter methodParam = BeanUtils.getWriteMethodParameter(pd);
// Do not allow eager init for type matching in case of a prioritized post-processor.
boolean eager = !(bw.getWrappedInstance() instanceof PriorityOrdered);
DependencyDescriptor desc = new AutowireByTypeDependencyDescriptor(methodParam, eager);
Object autowiredArgument = resolveDependency(desc, beanName, autowiredBeanNames, converter);
……
for (String autowiredBeanName : autowiredBeanNames) {
registerDependentBean(autowiredBeanName, beanName);
……解析方法参考resolveDependency方法
resolveDependency
方法继承自AutowireCapableBeanFactory,在DefaultListableBeanFactory中实现
首先if判断了几个特殊的依赖类型:Optional、ObjectFactory、javax.inject.Provider,非这几种类型的走常规流程:
Object result = getAutowireCandidateResolver().getLazyResolutionProxyIfNecessary(
descriptor, requestingBeanName);
if (result == null) {
result = doResolveDependency(descriptor, requestingBeanName, autowiredBeanNames, typeConverter);
}
return result;走到doResolveDependency方法
doResolveDependency
Object shortcut = descriptor.resolveShortcut(this);
if (shortcut != null) {
return shortcut;
}场景一、首先根据名称快速查找,这里是对应AutowiredAnnotationBeanPostProcessor处理@Autowired注解的流程,这里找到了就返回去。
if (value instanceof String) {
String strVal = resolveEmbeddedValue((String) value);
BeanDefinition bd = (beanName != null && containsBean(beanName) ?
getMergedBeanDefinition(beanName) : null);
// 解析SpEL表达式
value = evaluateBeanDefinitionString(strVal, bd);
}
场景二、这一步是对应QualifierAnnotationAutowireCandidateResolver处理@Value注解的流程,这里就能找得到,找到的话判断value是不是String类型,如果是,调用resolveEmbeddedValue方法解析出@Value注解属性值对应的真实值,因为@Value注解可能用于快速配置,真实值在配置文件application.properties中
spring-boot就是用的这一套流程
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
try {
return converter.convertIfNecessary(value, type, descriptor.getTypeDescriptor());
}
catch (UnsupportedOperationException ex) {
……如果上面@Value找到的值非String类型,这里基于注册的TypeConverter#convertIfNecessary做格式转换,点我跳转
Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}场景三、这一步是处理集合型依赖,例如Array、List、Set、Map,下层也是调用到findAutowireCandidates方法
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
……
if (matchingBeans.size() > 1) {
// 一个依赖匹配到一个bean
autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
……
}
else {
// 一个依赖匹配到多个bean,过滤
……
if (instanceCandidate instanceof Class) {
instanceCandidate = descriptor.resolveCandidate(autowiredBeanName, type, this);
}
……
}场景四、调用findAutowireCandidates方法查找单个依赖,如果单个依赖还找到了多个bean适配,还需要做过滤流程
resolveEmbeddedValue - 占位符解析
继承自AbstractBeanFactory
for (StringValueResolver resolver : this.embeddedValueResolvers) {
result = resolver.resolveStringValue(result);
if (result == null) {
return null;
}
}方法核心在这个for循环中,循环embeddedValueResolvers属性。这个属性中spring提供了一个默认的占位符解析器PropertySourcesPlaceholderConfigurer
可以看下这个属性加载的地方,在AbstractBeanFactory#addEmbeddedValueResolver
public void addEmbeddedValueResolver(StringValueResolver valueResolver) {
Assert.notNull(valueResolver, "StringValueResolver must not be null");
this.embeddedValueResolvers.add(valueResolver);
}继续找它的调用点PlaceholderConfigurerSupport#doProcessProperties
protected void doProcessProperties(ConfigurableListableBeanFactory beanFactoryToProcess,
StringValueResolver valueResolver) {
……
// New in Spring 3.0: resolve placeholders in embedded values such as annotation attributes.
beanFactoryToProcess.addEmbeddedValueResolver(valueResolver);
}再往上追溯可以看到PropertySourcesPlaceholderConfigurer#postProcessBeanFactory ,这个东西是很熟悉的,就是可插入式处理器BeanFactoryPostProcessor#postProcessBeanFactory ,关于它的介绍可以参考下链接:
spring-boot的配置项解析就是依赖这套加载逻辑执行的
applyPropertyValues
填充属性方法,继承自AbstractAutowireCapableBeanFactory
TypeConverter converter = getCustomTypeConverter();
if (converter == null) {
converter = bw;
}
BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this, beanName, mbd, converter);先判断是不是转了类型的属性,如果是直接塞,如果不是要加载自定义类型转换器和bean解析器
后面就是遍历property,先解析再转换。最后存入
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
Object convertedValue = resolvedValue;
boolean convertible = bw.isWritableProperty(propertyName) &&
!PropertyAccessorUtils.isNestedOrIndexedProperty(propertyName);
if (convertible) {
convertedValue = convertForProperty(resolvedValue, propertyName, bw, converter);
}这里参考BeanDefinitionValueResolver#resolveValueIfNecessary 方法,点我跳转
对于需要转换的类型的,参考方法convertForProperty
evaluateBeanDefinitionString
继承自AbstractBeanFactory,可见是一个很顶层的方法了
if (this.beanExpressionResolver == null) {
return value;
}
……
return this.beanExpressionResolver.evaluate(value, new BeanExpressionContext(this, scope));核心是这里,取资源编辑注册器属性private BeanExpressionResolver beanExpressionResolver ,继承自AbstractBeanFactory
如果注册了编辑器,则调用其BeanExpressionResolver#evaluate方法,否则直接返回原始值,点我跳转
资源编辑注册器的初始化是在AbstractApplicationContext#refresh流程的prepareBeanFactory方法中
initBeanWrapper
继承自AbstractBeanFactory
protected void initBeanWrapper(BeanWrapper bw) {
bw.setConversionService(getConversionService());
registerCustomEditors(bw);
}这里是为了初始化一些工具类,例如自定义的属性解析器,用于后面populateBean流程中注入属性时解析一些自定义的属性
这些特殊类型的解析器与ApplicationContext#refresh方法,prepareBeanFactory步骤加载的默认解析器功能一样,都是为了将一些String值解析成某些复杂类型的
这些复杂类型解析器的编写可以参考:
invokeAwareMethods
private void invokeAwareMethods(String beanName, Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware) {
ClassLoader bcl = getBeanClassLoader();
if (bcl != null) {
((BeanClassLoaderAware) bean).setBeanClassLoader(bcl);
}
}
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}代码比较简单,可以看出就是对实现Aware接口的bean做一些配置,包括beanName、beanFactory、beanClassLoader等
Aware接口比如BeanFactoryAware、ApplicationContextAware、ResourceLoaderAware、ServletContextAware等,是为了让bean有意识地知道自己是被谁创造的
public interface BeanFactoryAware extends Aware {
void setBeanFactory(BeanFactory beanFactory) throws BeansException;
}比如以下案例:
public class ControlServiceImpl implements IControlService, BeanFactoryAware {
private BeanFactory factory;
@Override
public void setBeanFactory(BeanFactory factory) {
this.factory = factory;
}
@Override
public OutputObject execute(InputObject inputObject) {
System.out.println("--------------ControlServiceImpl.execute()方法---------");
OutputObject outputObject = new OutputObject(ControlConstants.RETURN_CODE.IS_OK);
try {
outputObject.setReturnCode(ControlConstants.RETURN_CODE.IS_OK);
if (inputObject != null) {
Object object = factory.getBean(inputObject.getService());
Method mth = object.getClass().getMethod(inputObject.getMethod(), InputObject.class, OutputObject.class);
mth.invoke(object, inputObject, outputObject);
} else {
throw new Exception("InputObject can't be null !!!");
}
} catch (Exception e) {
// 异常处理
} finally {
}
return outputObject;
}
}这个案例中setBeanFactory在加载bean的时候自动调用,而execute就可以拿着beanFactory调用getBean方法,即时获取输入元素的bean,进而反射动态调用输入元素中的特有方法,省区了判断类型的if流程。
setBeanFactory方法实际被调用点就在invokeAwareMethods中
除了BeanFactoryAware,其他两个同理。
convertForProperty
承担了一些列类型转换的工作,例如把string类型转成resource[]类型,resources一般是spring中一个比较重要的配置项,而配置值都是使用String类型的路径,这里就需要用到了该方法
return ((BeanWrapperImpl) converter).convertForProperty(value, propertyName);后续实际转换的代码可以参考到TypeConverterDelegate#convertIfNecessary 点我跳转
invokeInitMethods
if (isInitializingBean && (mbd == null || !mbd.hasAnyExternallyManagedInitMethod("afterPropertiesSet"))) {
……
((InitializingBean) bean).afterPropertiesSet();
}
}首先判断是InitializingBean的实现类,是则激活InitializingBean#afterPropertiesSet 方法,其他扩展点可以参考:
if (mbd != null && bean.getClass() != NullBean.class) {
String initMethodName = mbd.getInitMethodName();
if (StringUtils.hasLength(initMethodName) &&
!(isInitializingBean && "afterPropertiesSet".equals(initMethodName)) &&
!mbd.hasAnyExternallyManagedInitMethod(initMethodName)) {
invokeCustomInitMethod(beanName, bean, mbd);
}
}这里判断bean配置了initMethod方法则调用对应的初始化方法
ConstructorResolver
instantiateUsingFactoryMethod
先创建,并初始化实例持有器BeanWrapper。
然后判断工厂是实例工厂还是静态工厂,这一部分最核心的代码如下:
String factoryBeanName = mbd.getFactoryBeanName();
if (factoryBeanName != null) {
……
factoryBean = this.beanFactory.getBean(factoryBeanName);
……
factoryClass = factoryBean.getClass();
isStatic = false;
}
else {
……
factoryBean = null;
factoryClass = mbd.getBeanClass();
isStatic = true;
}实际就是为了取出工厂的bean、工厂的class。
然后开始解析参数,这部分比较复杂,整体思路是:
如果有入参,就直接使用
没有入参,就找解析的参数
先考虑有工厂方法的情况,
如果有就取工厂方法的类,并从缓存中取解析出来的参数,
如果没解析过,就找工厂方法是否有重载,找候选排序最高的(public优先,参数多的优先)
然后根据构造器参数值解析参数,做一些列参数判断。
然后就是对候选方法的遍历,遍历过程中对每个候选方法计算权重。
for (Method candidate : candidates) {
……
if (paramTypes.length != explicitArgs.length) {
continue;
}
……
……
argsHolder = createArgumentArray(beanName, mbd, resolvedValues, bw,
……
……
}这里比较重要的是一开始判断参数个数,如果对不上就直接下一个,对上了后面创建参数列表holder
最后创建实例并配置到beanWrapper
bw.setBeanInstance(instantiate(beanName, mbd, factoryBean, factoryMethodToUse, argsToUse));return AccessController.doPrivileged((PrivilegedAction<Object>) () ->
strategy.instantiate(mbd, beanName, this.beanFactory, constructorToUse, argsToUse),然后下级再调用到SimpleInstantiationStrategy#instantiate ,点我跳转
autowireConstructor
与工厂方法的差异点在于:工厂方法会遍历所有的备选方法找出参数类型差异最小的,而自动装配构造找的一个满足条件的就停止。
备选方法的获取是来自bean的配置文件
try {
candidates = (mbd.isNonPublicAccessAllowed() ?
beanClass.getDeclaredConstructors() : beanClass.getConstructors());
}如果备选只有1个即无参构造,就直接开始构造了
if (candidates.length == 1 && explicitArgs == null && !mbd.hasConstructorArgumentValues()) {
……
bw.setBeanInstance(instantiate(beanName, mbd, uniqueCandidate, EMPTY_ARGS));
return bw;
}
}否则还是解析参数的流程,跟工厂类差不多。上来先找入参,没有看缓存是否解析过。没有再往下解析。解析过程中参数来源于配置文件
如果有多个备选构造函数,入参也解析完了,里面也是遍历算权重的流程,算完了之后也是调用初始化方法开始构造
if (mbd.hasConstructorArgumentValues()) {
ConstructorArgumentValues cargs = mbd.getConstructorArgumentValues();
……
}
……
for (Constructor<?> candidate : candidates) {
……
}
……
bw.setBeanInstance(instantiate(beanName, mbd, constructorToUse, argsToUse));然后instantiate再调用到调用到SimpleInstantiationStrategy#instantiate 点我跳转
return AccessController.doPrivileged((PrivilegedAction<Object>) () ->
strategy.instantiate(mbd, beanName, this.beanFactory, constructorToUse, argsToUse),SimpleInstantiationStrategy - 实例化策略
instantiate
分两个场景:
有lookup-method、replace标签的时候,就有MethodOverrides属性,用cglib代理的方式构造类。动态代理和切面相关见后
没有MethodOverrides的时候直接反射构造类
if (!bd.hasMethodOverrides()) {
……
return BeanUtils.instantiateClass(constructorToUse);
}
else {
// Must generate CGLIB subclass.
return instantiateWithMethodInjection(bd, beanName, owner);
}BeanDefinitionValueResolver
BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this, beanName, mbd, converter);
……
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);在bean加载过程中,属性填充DefaultListableBeanFactory#populateBean方法找到属性对应的bean后,调用applyProertyValues方法解析属性值,就用到属性解析器。
resolveValueIfNecessary
给定一个PropertyValue,返回一个value,解析对工厂中其他bean的引用。
在这个方法中主体就是通过多个if-else if-else组织的,根据不同场景委托给不同方法
value可能是:
RuntimeBeanReference : 在解析到依赖的Bean的时侯,解析器会依据依赖bean的name创建一个RuntimeBeanReference对像,将这个对像放入BeanDefinition的MutablePropertyValues中
RuntimeBeanNameReference
BeanDefinitionHolder、BeanDefinition:均调用resolveInnerBean方法分析
DependencyDescriptor
ManagedArray:用来保存它所管理的Array元素,它可以包含运行时期的bean的引用(将被解析为bean对象).
ManagedList:用来保存它所管理的List元素,它可以包含运行时期的bean引用(将被解析为bean对象).
ManagedSet :用来保存它所管理的set值,它可以包含运行时期的bean引用(将被解析为bean对象)
ManagedMap :用来保存它所管理的map值,它可以包含运行时期的bean引用(将被解析为bean对象)
以ManagedArray为例:
return resolveManagedArray(argName, (List<?>) value, elementType);private Object resolveManagedArray(Object argName, List<?> ml, Class<?> elementType) {
Object resolved = Array.newInstance(elementType, ml.size());
for (int i = 0; i < ml.size(); i++) {
Array.set(resolved, i, resolveValueIfNecessary(new KeyedArgName(argName, i), ml.get(i)));
}
return resolved;
}可以看到下面又递归调用了BeanDefinitionValueResolver#resolveValueIfNecessary ,其实也好理解,是因为需要解析稽核类型中的元素的最终类型,到最底层都是在把依赖bean解析成String
看RuntimeBeanNameReference这个场景可见端倪:
else if (value instanceof RuntimeBeanNameReference) {
String refName = ((RuntimeBeanNameReference) value).getBeanName();
// 核心在这里
refName = String.valueOf(doEvaluate(refName));
if (!this.beanFactory.containsBean(refName)) {
throw new BeanDefinitionStoreException(
"Invalid bean name '" + refName + "' in bean reference for " + argName);
}
return refName;
}是通过doEvaluate方法解析的
evaluate/doEvaluate
evaluate方法最终也会调用到doEvaluate方法中
private Object doEvaluate(@Nullable String value) {
return this.beanFactory.evaluateBeanDefinitionString(value, this.beanDefinition);
}而这里又回调到了DefaultListableBeanFactory#evaluateBeanDefinitionString 点我跳转
AbstractAutoProxyCreator - 早期/后期处理器
getEarlyBeanReference
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
return wrapIfNecessary(bean, beanName, cacheKey);
}方法看起来很简单,就是从内存中获取bean
它的核心在earlyProxyReferences这个成员属性,那这个earlyProxyReferences存进去又是在哪用的呢?看它的移除方法:
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}可知AbstractAutoProxyCreator实现了BeanPostProcessor#postProcessAfterInitialization ,在初始化后调用把内存清理掉
它的调用点在AbstractAutowireCapableBeanFactory#applyBeanPostProcessorsAfterInitialization ,而此方法调用就比较多了:
bean创建前提前获取bean的时候
AbstractAutowireCapableBeanFactory#resolveBeforeInstantiationinitializeBean前断路操作,以及initailzeBean后的后置操作
TypeConverterDelegate - 类型转换框架
convertIfNecessary
// Custom editor for this type?
PropertyEditor editor = this.propertyEditorRegistry.findCustomEditor(requiredType, propertyName);首先找自定义的转换器。自定义转换器是继承了PropertyEditor的自定义工具类,它被加载到上下文中是在容器AbstractApplicationContext#refresh流程中的prepareRefresh步骤
如果找不到自定义转换器,后面会取默认的,spring默认提供的转换器就是由String转成ResourceArray的转换器
if (editor == null) {
editor = findDefaultEditor(requiredType);
}
convertedValue = doConvertValue(oldValue, convertedValue, requiredType, editor);而继续跟进doConvertValue方法
// ------------------doConvertValue----------------------
if (convertedValue instanceof String) {
……
return doConvertTextValue(oldValue, newTextValue, editor);发现对于String类型的结果,调用doConvertTextValue方法
private Object doConvertTextValue(@Nullable Object oldValue, String newTextValue, PropertyEditor editor) {
……
editor.setAsText(newTextValue);
return editor.getValue();
}这里以ResourceArrayPropertyEditor#setAsText 方法为例
ResourceArrayPropertyEditor
setAsText
public void setAsText(String text) {
String pattern = resolvePath(text).trim();
try {
setValue(this.resourcePatternResolver.getResources(pattern));
}
catch ……
}到这里就比较明显了,是通过PathMatchingResourcePatternResolver#getResource做资源列表的解析。前面也分析过了。
AutowiredAnnotationBeanPostProcessor - @Autowired注解处理器
核心成员变量
维护了一个依赖注入元数据的缓存
private final Map<String, InjectionMetadata> injectionMetadataCache = new ConcurrentHashMap<>(256);postProcessMergedBeanDefinition
实现了MergedBeanDefinitionPostProcessor#postProcessMergedBeanDefinition 接口方法,处理特殊的BD
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
InjectionMetadata metadata = findAutowiringMetadata(beanName, beanType, null);
metadata.checkConfigMembers(beanDefinition);
}统一调用了findAutowiringMetadata方法
postProcessProperties
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);
try {
metadata.inject(bean, beanName, pvs);
}
catch (BeanCreationException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", ex);
}
return pvs;
}从AbstractAutowireCapableBeanFactory#populateBean 属性注入流程中调用进来
与postProcessMergedBeanDefinition方法一样,都基于findAutowiringMetadata方法做
findAutowiringMetadata
注解扫描的核心方法
InjectionMetadata metadata = this.injectionMetadataCache.get(cacheKey);如果已经扫过,都会存在injectionMetadataCache缓存里面,因此先从缓存中取
synchronized (this.injectionMetadataCache) {
metadata = this.injectionMetadataCache.get(cacheKey);
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
……
metadata = buildAutowiringMetadata(clazz);
this.injectionMetadataCache.put(cacheKey, metadata);
}
}如果缓存中没有,这里synchronized加锁做双判,然后调用buildAutowiringMetadata扫描并构造,然后存入缓存
buildAutowiringMetadata
方法的主体逻辑就是一个do-while循环
do {
// 处理@Autowired属性
final List<InjectionMetadata.InjectedElement> fieldElements = new ArrayList<>();
ReflectionUtils.doWithLocalFields(targetClass, field -> {
MergedAnnotation<?> ann = findAutowiredAnnotation(field);
……
boolean required = determineRequiredStatus(ann);
fieldElements.add(new AutowiredFieldElement(field, required));
}
});
final List<InjectionMetadata.InjectedElement> methodElements = new ArrayList<>();
ReflectionUtils.doWithLocalMethods(targetClass, method -> {
……
// 处理桥接方法
});
……
// 找父类
targetClass = targetClass.getSuperclass();
}
while (targetClass != null && targetClass != Object.class);可以看到方法的主体部分,对每个类中的@Autowired属性和桥接方法,例如被注解了@Autowired方法的set方法,分别处理
最后一圈走完,有一个核心的地方就是取父类,这样使得子类可以注入父类标记了@Autowired的变量
解决bean的循环依赖
循环依赖的分类:自依赖、直接依赖、间接依赖。
spring对循环依赖的处理有三种情况:构造器循环依赖、setter循环依赖、
构造器循环依赖
例如以下配置:
<bean id="testA" class="com.bean.TestA">
<constructor-arg index="0" ref="testB"/>
</bean>
<bean id="testB" class="com.bean.TestB">
<constructor-arg index="0" ref="testC"/>
</bean>
<bean id="testC" class="com.bean.TestC">
<constructor-arg index="0" ref="testA"/>
</bean>对于这种情况,spring只能抛出BeanCurrentlyInCreationException异常,研发过程中需要使用@Lazy等方式解决。
setter循环依赖
或者说是@Autowired产生的循环依赖
对于这种情况,spring只能处理单例bean的循环依赖问题,即通过三级缓存解决:
三级缓存可以在DefaultListableBeanFactory中找到,是继承自DefaultSingletonBeanRegistry
三级缓存
一级缓存singletonObjects:最基础的单例缓存,限制 bean 在 beanFactory 中只存一份,即实现 singleton scope
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);二级缓存earlySingletonObjects:看名字应该就能猜到是未初始化未填充属性提前暴露的Bean,是与三级缓存配合使用的。这里如果发现bean是AOP代理的,保存的就是代理的bean实例beanProxy,目标bean还是半成品
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);三级缓存singletonFactories:Bean创建时提供代理机会的Bean工厂缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);基于这种设计,没有发生循环依赖的bean就是正常的创建流程。相互引用的bean 会触发链路中最初结点放入三级缓存内容,调用getEarlyBeanReference 返回相应对象
spring解决的逻辑如下:创建beanA时暴露singletonFactory存入一级缓存,先根据无参构造创建一个earlySingletonObject存入二级缓存,注入依赖beanA的beanB,最终创建好singletonObject,重新注入beanA,存入三级缓存。
三级缓存相关方法
// 方法一、DefaultSingletonBeanRegistry#addSingletonFactory
protected void addSingletonFactory(String beanName, ObjectFactory singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
// 方法二、DefaultSingletonBeanRegistry#getSingleton
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
// 方法三、DefaultSingletonBeanRegistry#addSingleton
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, (singletonObject != null ? singletonObject : NULL_OBJECT));
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
DefaultSingletonBeanRegistry#addSingletonFactory:FactoryBean存入三级缓存,同时确保二级缓存中没有初始状态的beanDefaultSingletonBeanRegistry#getSingleton:调用FactoryBean.getObject方法创建bean,存入二级缓存,移除三级缓存中的工厂beanDefaultSingletonBeanRegistry#addSingleton:存入一级缓存,二级、三级缓存都移除对应早期bean和工厂bean
三级缓存相关方法的调用点
调用点1 AbstractBeanFactory#doGetBean开始阶段调用DefaultSingletonBeanRegistry#getSingleton 尝试获取之前创建好的不完整单例,当这里拿不到,才会往后走触发getSingleton流程并且调用createBean方法
// Eagerly check singleton cache for manually registered singletons.
Object sharedInstance = getSingleton(beanName);调用点2 AbstractAutowireCapableBeanFactory#doCreateBean 方法执行完第一步createBeanInstance后,判断需要暴露bean工厂,执行DefaultSingletonBeanRegistry#addSingletonFactory ,这时候还没有执行populateBean和initializeBean
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}调用点3 AbstractAutowireCapableBeanFactory#doCreateBean方法完成bean初始化三步后,此时可能还有bean依赖的其他未创建的bean,则这个bean是不完整的,此时暴露bean的早期实例,调用DefaultSingletonBeanRegistry#getSingleton ,调用后工厂bean移除,初始状态bean存入二级缓存
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);调用点4 依赖bean也创建完,给这个bean整体配置好后,回到AbstractBeanFactory#doGetBean的getSingleton方法后,走到getObejct方法后,存入完整bean,调用方法DefaultSingletonBeanRegistry#addSingleton
protected <T> T doGetBean(
String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly)
throws BeansException {
……
// Create bean instance.
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) ……
});
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
……// ---------DefaultSingletonBeanRegistry#getSingleton--------------------------
if (newSingleton) {
addSingleton(beanName, singletonObject);
}prototype循环依赖
spring无法完成处理,因为prototype作用域的bean不进行缓存。一般可以通过setAllowCircularReferences为false来禁用循环引用。
评论区