


本篇以一个最基础的问题作为主线:如何实现一个最简单的spring-bean?
通过Class+xml配置文件就可以做到:
// BeanClass
public class MyTestBean {
private String testStr = "testStr";
public String getTestStr() {
return testStr;
}
public void setTestStr(String testStr) {
this.testStr = testStr;
}
}<!-- spring-beans.xml -->
<?xml version = "1.0" encoding = "UTF-8"?>
<!-- 增加额外扫包 -->
<context:component-scan base-package="com.foo" use-default-filters="false">
<context:include-filter type="regex" expression="com.foo.bar.*Config"/>
<context:include-filter type="regex" expression="com.foo.config.*"/>
</context:component-scan>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http">
<bean id="myTestBean" class="test.MyTestBean"/>
</beans>现在我们可以加一个main方法,用于获取这个bean:
// 启动类 - 完成spring从xml读取bean的配置
public class MyTest {
@SuppressWarnings("deprecation")
@Test
public void testSimpleLoad() {
BeanFactory bf = new XmlBeanFactory(new ClassPathResource("spring-beans.xml"));
MyTestBean bean = (MyTestBean) bf.getBean("myTestBean");
System.out.println(bean.getTestStr());
}
}可以看到,只使用了一个最简单的方法new XmlBeanFactory(new ClassPathResource("spring-beans.xml")),我们就获取了一个BeanFactory,并且从这个BeanFactory中取出了我们想要的bean
那么问题来了:
1、xml是如何被加载成BeanFactory的?
2、BeanFactory是如何取出我想要的Bean的
本篇先分析第一个问题:xml被加载成BeanFactory的流程
用于Xml配置文件读取的相关类
XmlBeanFactory
XmlBeanFactory的血缘
前面说过DefaultListableBeanFactory是各种自定义BeanFactory的父类,XmlBeanFactory就继承自DefaultListableBeanFactory,对后者进行了扩展
XmlBeanFactory主要增加的是从XML文档中读取BeanDefinition的能力,而注册和获取Bean的方法都是继承自父类做实现的
XmlBeanFactory增加了XmlBeanDefinitionReader类型的reader属性,用于对资源文件进行读取和注册。
它生成BeanFactory的时序图如下:
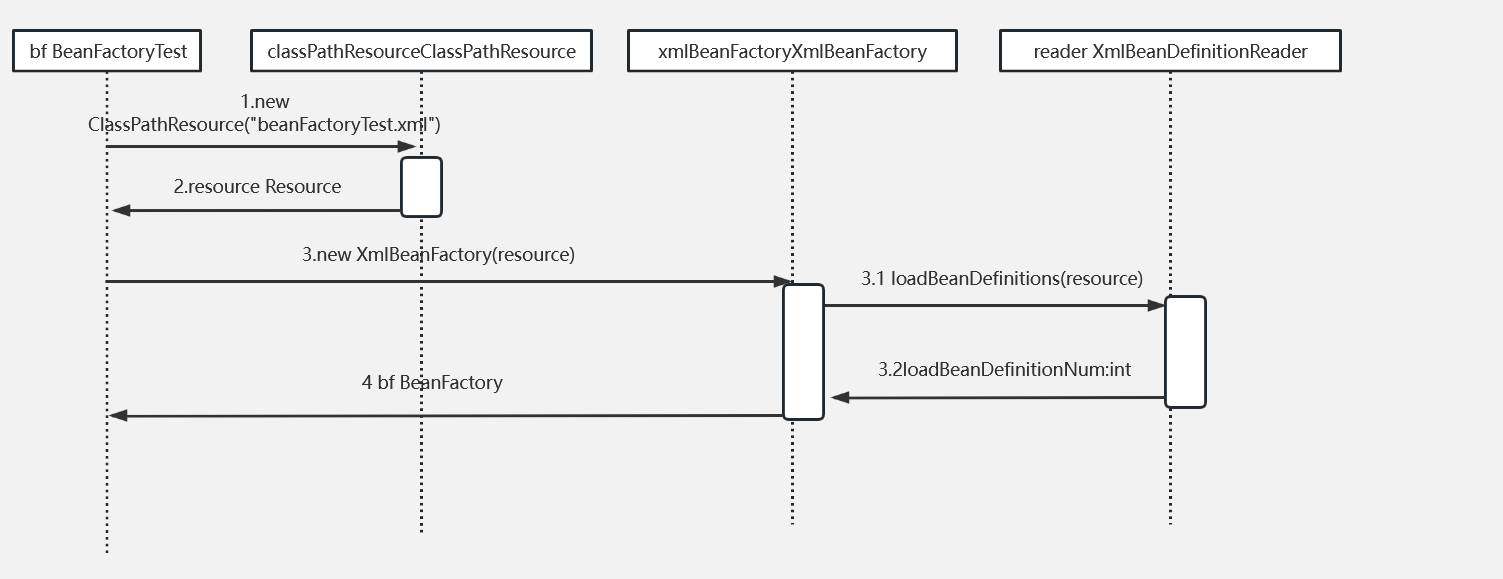
构造函数
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
this.reader.loadBeanDefinitions(resource);
}其中parentBeanFactory用于factory合并,可以为空
核心方法即调用父类的初始化方法,以及XmlBeanDefinitionReader::loadBeanDefinitions方法
继续看父类的初始化方法,一直找到AbstractAutowireCapableBeanFactory
public AbstractAutowireCapableBeanFactory() {
super();
ignoreDependencyInterface(BeanNameAware.class);
ignoreDependencyInterface(BeanFactoryAware.class);
ignoreDependencyInterface(BeanClassLoaderAware.class);
if (NativeDetector.inNativeImage()) {
this.instantiationStrategy = new SimpleInstantiationStrategy();
}
else {
this.instantiationStrategy = new CglibSubclassingInstantiationStrategy();
}
}ignoreDependencyInterface的主要功能是忽略给定接⼝的⾃动装配功能。例如:
当A中有属性B,那么当Spring在获取A的Bean的时候如果其属性B还没有初始化,那么Spring会⾃动初始化B,这也是Spring中提供的⼀个重要特性。但是,某些情况下,B不会被初始化,其中的⼀种情况就是B实现了BeanNameAware接⼝。
Spring中是这样介绍的:⾃动装配时忽略给定的依赖接⼝,典型应⽤是通过其他⽅式解析Application上下⽂注册依赖,类似于BeanFactory通过BeanFactoryAware进⾏注⼊或者ApplicationContext通过ApplicationContextAware进⾏注⼊。
XmlBeanDefinitionReader
XmlBeanDefinitionReader的血缘
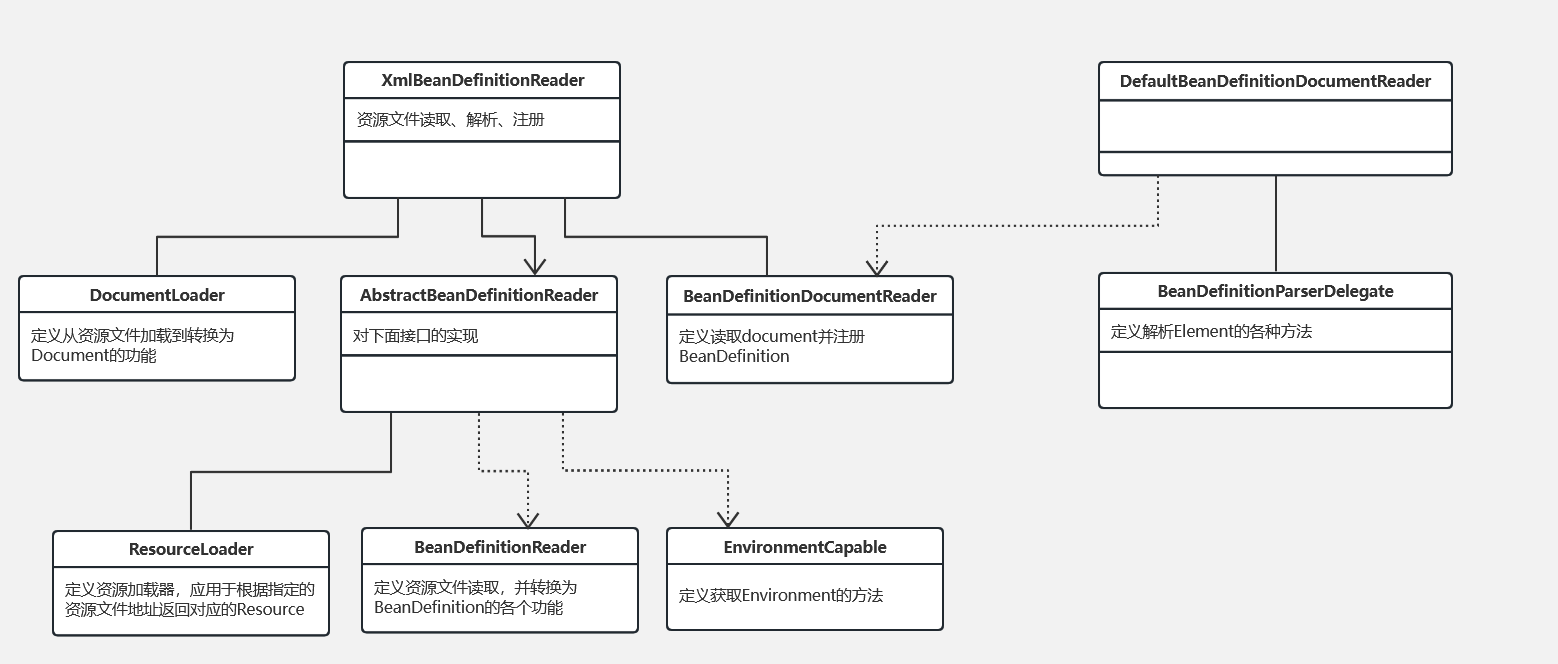
loadBeanDefinitions
这个方法是有很多多态版本,首先是上面直接用到的解析Resource类的,会将Resource编码转化成EncodedResource
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}这个方法还支持对String类型的xml配置文件路径做处理,处理的时候要转化成Resource类型,再继续处理
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException {
……
// 支持模糊匹配是在于ResourcePatternResolver匹配
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
int count = loadBeanDefinitions(resources);在处理这类String类型的location的时候,是支持模糊匹配的,因为这里通过ResourcePatternResolver#getResources方法进行匹配,这里resourceLoader的来源是在构造函数里
protected AbstractBeanDefinitionReader(BeanDefinitionRegistry registry) {
……
this.resourceLoader = new PathMatchingResourcePatternResolver();
……
}因此这里可以直接参考PathMatchingResourcePatternResolver#getResources 方法即可,见PathMatchingResourcePatternResolver
最后是直接解析EncodedResoruce类的
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
……
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
……
}doLoadBeanDfinitions - 核心中的核心
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
Document doc = doLoadDocument(inputSource, resource);
int count = registerBeanDefinitions(doc, resource);
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + count + " bean definitions from " + resource);
}
return count;
}protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}这里一共做了三个核心步骤,这三个步骤支撑了spring整个容器部分的实现:
获取对XML⽂件的验证模式:
XmlBeanDefinitionReader#getValidationModeForResource加载XML⽂件,并得到对应的Document:
DocumentLoader#loadDocument,这里作为参数还传了一个EntityResolver(配置文件解析器)进去,通过XmlBeanDefinitionReader#getEntityResolver获取,见下面根据返回的Document注册Bean信息:
XmlBeanDefinitionReader#registerBeanDefinitions,见下面
getValidationModeForResource - 验证文件模式
protected int getValidationModeForResource(Resource resource) {
int validationModeToUse = getValidationMode();
if (validationModeToUse != VALIDATION_AUTO) {
return validationModeToUse;
}
int detectedMode = detectValidationMode(resource);
if (detectedMode != VALIDATION_AUTO) {
return detectedMode;
}
return VALIDATION_XSD;
}可以看到是校验是否是AUTO自动模式,如果直接取取不到,会调用detectValidationMode方法
protected int detectValidationMode(Resource resource) {
……
InputStream inputStream;
try {
inputStream = resource.getInputStream();
}
……
try {
return this.validationModeDetector.detectValidationMode(inputStream);
}这里只是一个框架,核心是在XmlValidationModeDetector#detectValidationMode ,见对应部分
getEntityResolver
protected EntityResolver getEntityResolver() {
if (this.entityResolver == null) {
……
if (resourceLoader != null) {
this.entityResolver = new ResourceEntityResolver(resourceLoader);
}
else {
this.entityResolver = new DelegatingEntityResolver(getBeanClassLoader());
}
}
return this.entityResolver;
}有两个方法获取EntityResolver,但是实际上都是调用到DelegatingEntityResolver
根据该方法的分析,我们得知,目前拿到了一个存储着spring的xml中标签的命名空间对应其定义的schema文件的对应位置信息的一个解析器,下面就该用这个解析器解析我们的配置文件了
registerBeanDefinitions - 注册Bean信息
注册BeanDefinition的入口,拿前面SAX解析xml配置文件的得到的Document加载得到BD
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}首先调用XmlBeanDefinitionReader#createBeanDefinitionDocumentReader 方法创建BeanDefinitionDocumentReader,这里如果不调整,也是用的默认值
private Class<? extends BeanDefinitionDocumentReader> documentReaderClass =
DefaultBeanDefinitionDocumentReader.class;然后解析方法委托DefaultBeanDefinitionDocumentReader#doRegisterBeanDefinitions 见DefaultBeanDefinitionDocumentReader
PathMatchingResourcePatternResolver
大纲
继承ResourcePatternResolver,重写了getResources方法
核心成员变量包括:
String CLASSPATH_ALL_URL_PREFIX = "classpath*:";从父类继承来了一个CLASSPATH的前缀,因此可以知道spring的配置文件中为什么默认以classpath*开头了,我们配置成classpath*:xx/*.xml就可以解析该路径下所有的xml了
getResources - 资源解析的框架方法
if (locationPattern.startsWith(CLASSPATH_ALL_URL_PREFIX)) {
// a class path resource (multiple resources for same name possible)
if (getPathMatcher().isPattern(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()))) {
// a class path resource pattern
return findPathMatchingResources(locationPattern);
}
else {
// all class path resources with the given name
return findAllClassPathResources(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()));
}
}首先判断是以首先判断以classpath*:开头,对于这种分别有两个处理逻辑:
所有路径都给了真实路径,调用
findPathMatchingResources方法,直接匹配真是路径通过模糊匹配去查找,调用
findAllClassPathResources(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()))匹配模糊路径
对于如果非classpath*开头的还有判断是否以war:开头。
int prefixEnd = (locationPattern.startsWith("war:") ? locationPattern.indexOf("*/") + 1 :
locationPattern.indexOf(':') + 1);
if (getPathMatcher().isPattern(locationPattern.substring(prefixEnd))) {
// a file pattern
return findPathMatchingResources(locationPattern);
}
else {
// a single resource with the given name
return new Resource[] {getResourceLoader().getResource(locationPattern)};
}findPathMatchingResources - 模糊匹配路径
模糊匹配路径这块可以重点看下,mybatis集成的原理就来自于这里的逻辑
首先分析出模糊路径里面的父目录和模糊匹配的部分,例如classpath*:test/*.xml中,父目录就是test,模糊匹配的部分是*.xml
遍历父目录,找以下四种:
bundle开头的
if (equinoxResolveMethod != null && rootDirUrl.getProtocol().startsWith("bundle")) {
……vfs类型
if (rootDirUrl.getProtocol().startsWith(ResourceUtils.URL_PROTOCOL_VFS)) {
result.addAll(VfsResourceMatchingDelegate.findMatchingResources(rootDirUrl, subPattern,
getPathMatcher()));
}jar类型
else if (ResourceUtils.isJarURL(rootDirUrl) || isJarResource(rootDirResource)) {
result.addAll(doFindPathMatchingJarResources(rootDirResource, rootDirUrl, subPattern));
}剩下的就是xml的
else {
result.addAll(doFindPathMatchingFileResources(rootDirResource, subPattern));
}这里向下调用到了PathMatchingResourcePatternResolver#retrieveMatchingFiles
retrieveMatchingFiles
protected Set<File> retrieveMatchingFiles(File rootDir, String pattern) throws IOException {
……
doRetrieveMatchingFiles(fullPattern, rootDir, result);
return result;
}对于传入的File是一个根目录的情况
protected void doRetrieveMatchingFiles(String fullPattern, File dir, Set<File> result) throws IOException {
……
for (File content : listDirectory(dir)) {
String currPath = StringUtils.replace(content.getAbsolutePath(), File.separator, "/");
if (content.isDirectory() && getPathMatcher().matchStart(fullPattern, currPath + "/")) {
if (!content.canRead()) {
if (logger.isDebugEnabled()) {
logger.debug("Skipping subdirectory [" + dir.getAbsolutePath() +
"] because the application is not allowed to read the directory");
}
}
else {
doRetrieveMatchingFiles(fullPattern, content, result);
}
}
if (getPathMatcher().match(fullPattern, currPath)) {
result.add(content);
}
}
}通过for循环list文件匹配,这里list到的结果,就不允许再当成目录了,即只允许模糊匹配一层
EncodedResource
通过传入charset、encoding或什么都不传进行解码,最终的目的是获取到java.io.Reader。核心方法getReader可以看到判断过程
public Reader getReader() throws IOException {
if (this.charset != null) {
return new InputStreamReader(this.resource.getInputStream(), this.charset);
}
else if (this.encoding != null) {
return new InputStreamReader(this.resource.getInputStream(), this.encoding);
}
else {
return new InputStreamReader(this.resource.getInputStream());
}
}更底层调用的是nio包提供的StreamDecoder::forInputStreamReader方法
XmlValidationModeDetector
detectValidationMode - 验证文件模式
public int detectValidationMode(InputStream inputStream) throws IOException {
……
try (BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream))) {
boolean isDtdValidated = false;
String content;
while ((content = reader.readLine()) != null) {
……
if (hasDoctype(content)) {
isDtdValidated = true;
break;
}
if (hasOpeningTag(content)) {
// End of meaningful data...
break;
}
}
return (isDtdValidated ? VALIDATION_DTD : VALIDATION_XSD);
……
}可以看到大体逻辑就是基于BIO实现的,逐行读取,并且校验内容里面是否有一些特殊字符,最终确认配置文件是属于那个类型:
DTD - Document Type Definition文档类型
是⼀种XML约束模式语⾔,是XML⽂件的验证机制,属于XML⽂件组成的⼀部分。⼀个DTD⽂档包含:元素的定义规则,元素间关系的定义规则,元素可使⽤的属性,可使⽤的实体或符号规则。该模式需要在xml中增加类型声明配置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//Spring//DTD BEAN 2.0//EN"
"http://www.Springframework.org/dtd/ Spring-beans-2.0.dtd">
<beans>
… …
<beans>XSD(Schema) - Xml Schemas Defnition文档类型
XML Schema描述了XML⽂档的结构。可以⽤⼀个指定的XML Schema来验证某个XML文档。除了要声明名称空间外,
xmlns=http://www.Springframework.org/schema/beans还必须指定该名称空间所对应的XML Schema⽂档的存储位置。通过schemaLocation属性来指定名称空间所对应的XML Schema⽂档的存储位置,它包含两个部分,⼀部分是名称空间的URI,⼀部分就是该名称空间所标识的XML Schema⽂件位置或URL地址
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.Springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.Springframework.org/schema/beans
http://www.Springframework.org/schema/beans/Spring-beans.xsd">
... ...
</beans>Spring⽤来检测验证模式的办法在hasDoctype方法里面,就是判断是否包含DOCTYPE,如果包含就是DTD,否则就是XSD
private boolean hasDoctype(String content) {
return content.contains(DOCTYPE);
}DelegatingEntityResolver - xml约束加载器
什么是xml约束
一般xml文件的六个部分:文档声明、元素、属性、注释、CDATA区、处理指令。对于xml的标签要有一定约束,不然每个人都用自己的喜好定义,框架读取就没办法解析了。上面提到的DTD和XSD就是典型的两种约束方式
目前XSD已经逐渐取代了DTD,对命名空间的支持性较好。
根据SAX的要求,继承EntityResolver接口实现resolveEntity方法可以进行自定义解析器,且必须使用setEntityResolver方法向SAX驱动器注册自定义的解析器实例(在XmlBeanDefinitionReader#getEntityResolver中做的)
xml的具体约束包括:
xml命名空间约束
XML 命名空间将 XML 文档中的元素和属性名称与自定义和预定义的 URI 关联起来。 要创建这些关联,应为命名空间 URI 定义前缀,并使用这些前缀来限定 XML 数据中的元素和属性名称。 命名空间可防止元素和属性名称冲突,并允许以不同方式处理和验证同名的元素和属性。声明如下:
xmlns:<name>=<"uri">其中,<name> 是命名空间前缀,<"uri"> 是用于标识命名空间的 URI。 在声明前缀后,可使用该前缀来限定 XML 文档中的元素和属性,并将它们与命名空间 URI 相关联。 因为命名空间前缀在整个文档中使用,所以它的长度应较短。例如:
<mybook:BOOK xmlns:mybook="http://www.contoso.com/books.dtd">
<bb:BOOK xmlns:bb="urn:blueyonderairlines" />
</mybook:BOOK>这里定义两个 BOOK 元素。 第一个元素由前缀 mybook 限定,第二个元素由前缀 bb 限定。 每个前缀都与不同的命名空间 URI 相关联。
这就意味着,我们可以从http://www.contoso.com/books.dtd 找到mybook:BOOK 标签的定义,bb:BOOK同理
再来看spring的案例,便携spring配置文件时添加的
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:task="http://www.springframework.org/schema/task"
xmlns:jdbc="http://www.springframework.org/schema/jdbc"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.0.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-4.0.xsd
http://www.springframework.org/schema/task
http://www.springframework.org/schema/task/spring-task-4.0.xsd
http://www.springframework.org/schema/jdbc
http://www.springframework.org/schema/jdbc/spring-jdbc.xsd
http://www.springframework.org/schema/mvc
https://www.springframework.org/schema/mvc/spring-mvc.xsd">首先在spring的配置文件中,我们的主题使用的是<beans>标签,在引用时,首先以缩略格式声明了它的命名空间:
xmlns="http://www.springframework.org/schema/beans"
然后进而引入了xsi、context、aop、task、jdbc、mvc这几个标签的命名空间
然后使用xsi:schemaLocation 属性引入空间下的具体xsd规范,这个属性的格式是uri1 uri1-file uri2 uri2-file……,即beans下面读4.0.xsd,context下面读4.0.xsd依次类推
那么每个项目读取这些xml时是否意味着必须要访问该地址下载?事实上是不用的,约束文件已经存放到了本地。在spring-beans包的resources/META-INF/spring.schemas下文件中指明了路径:
……
http\://www.springframework.org/schema/beans/spring-beans-4.0.xsd=org/springframework/beans/factory/xml/spring-beans.xsd
http\://www.springframework.org/schema/beans/spring-beans-4.3.xsd=org/springframework/beans/factory/xml/spring-beans.xsd
http\://www.springframework.org/schema/beans/spring-beans.xsd=org/springframework/beans/factory/xml/spring-beans.xsd
http\://www.springframework.org/schema/tool/spring-tool-2.0.xsd=org/springframework/beans/factory/xml/spring-tool.xsd
……即如果我要使用spring-beans-4.0这个uri中的规范,我就去找org/springframework/beans/factory/xml/spring-beans.xsd 这个文件,至于这个文件是如何被加载到的,可以继续看,直到PluggableSchemaResolver#getSchemaMappings方法中
EntityResolver的默认实现
public DelegatingEntityResolver(@Nullable ClassLoader classLoader) {
this.dtdResolver = new BeansDtdResolver();
this.schemaResolver = new PluggableSchemaResolver(classLoader);
}这里可以看到,内部DTD处理器和XSD处理器分别使用了BeansDtdResolver类和PluggableSchemaResolver类。
DelegatingEntityRsolver实现了SAX核心的EntityResolver接口,实现resolveEntity方法,这个方法是SAX解析xml的入口方法,暂时不关心在何处调用。重写如下:
DelegatingEntityResolver#resolveEntity
public InputSource resolveEntity(@Nullable String publicId, @Nullable String systemId)
throws SAXException, IOException {
if (systemId != null) {
if (systemId.endsWith(DTD_SUFFIX)) {
return this.dtdResolver.resolveEntity(publicId, systemId);
}
else if (systemId.endsWith(XSD_SUFFIX)) {
return this.schemaResolver.resolveEntity(publicId, systemId);
}
}
// Fall back to the parser's default behavior.
return null;
}可见DelegatingEntityResolver实际上是承担了一个分发器的作用
根据systemId是DTD还是XSD选择对应的处理器调用resolveEntity方法,即上面构造函数传入的两种不同的处理器。这里入参传入的publicId和systemId。是SAX解析XML的两个底层概念
对于DTD:
<!DOCTYPE beans PUBLIC "-//Spring//DTD BEAN 2.0//EN"
"http://www.Springframework. org/dtd/Spring-beans-2.0.dtd">publicId: -//Spring//DTD BEAN 2.0//EN
systemId:http://www.springframework.org/dtd/Spring-beans-2.0.dtd
对于XSD:
xsi:schemaLocation="http://www.Springframework.org/schema/beans
http://www.springframework.org/schema/beans/Spring-beans.xsd”>publicId: null
systemId:http://www.springframework.org/schema/beans/Spring-beans.xsd
因为XSD的格式比较常用,重点看下
PluggableSchemaResolver#resolveEntiry - XSD的解析
if (systemId != null) {
String resourceLocation = getSchemaMappings().get(systemId);
if (resourceLocation == null && systemId.startsWith("https:")) {
// Retrieve canonical http schema mapping even for https declaration
resourceLocation = getSchemaMappings().get("http:" + systemId.substring(6));
}这里是从getSchemaMappings方法获取systemId对应的模式映射,然后基于https加载(也得先基于http映射一次),如果加载不处理则改用http加载
if (resourceLocation != null) {
Resource resource = new ClassPathResource(resourceLocation, this.classLoader);
try {
InputSource source = new InputSource(resource.getInputStream());
source.setPublicId(publicId);
source.setSystemId(systemId);
if (logger.isTraceEnabled()) {
logger.trace("Found XML schema [" + systemId + "] in classpath: " + resourceLocation);
}
return source;
}这一部分是把模式映射规范文件加载成Resource,并解析成InputSource
PluggableSchemaResolver#getSchemaMappings
private Map<String, String> getSchemaMappings() {
Map<String, String> schemaMappings = this.schemaMappings;
if (schemaMappings == null) {
……
try {
// 从schemaMappingsLocation中加载properties,最终封装成map
Properties mappings =
PropertiesLoaderUtils.loadAllProperties(this.schemaMappingsLocation, this.classLoader);
if (logger.isTraceEnabled()) {
logger.trace("Loaded schema mappings: " + mappings);
}
schemaMappings = new ConcurrentHashMap<>(mappings.size());
CollectionUtils.mergePropertiesIntoMap(mappings, schemaMappings);
this.schemaMappings = schemaMappings;
}
catch (IOException ex) {
throw new IllegalStateException(
"Unable to load schema mappings from location [" + this.schemaMappingsLocation + "]", ex);
}
}
}
}
return schemaMappings;
}新加载SchemaMappings的流程是通过schemaMappingLocation这个属性加载对应的稳定,使用PropertiesLoaderUtils#loadAllProperties 可以快速加载
看schemaMappingLocation的初始化,是在构造函数中
public PluggableSchemaResolver(@Nullable ClassLoader classLoader) {
this.classLoader = classLoader;
this.schemaMappingsLocation = DEFAULT_SCHEMA_MAPPINGS_LOCATION;
}它指向了一个默认常量:
public static final String DEFAULT_SCHEMA_MAPPINGS_LOCATION = "META-INF/spring.schemas";至此,可以明白是从spring.schemas中加载kv成map,然后从map中就可以找到XSD命名空间地址对应的模式映射
DefaultDocumentLoader
loadDocument - 加载XML
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isTraceEnabled()) {
logger.trace("Using JAXP provider [" + factory.getClass().getName() + "]");
}
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
return builder.parse(inputSource);
}这套流程是基于SAX解析xml文件的通用套路,可以学习一下:
DefaultDocumentLoader#createDocumentBuilderFactory方法创建DocumentBuilderFactoryDefaultDocumentLoader#createDocumentBuilder方法通过DocumentBuilderFactory创建DocumentBuilderDocumentBuilder#parse方法解析inputSource返回Document对象
解析后的结果封装成Documet对象,用于后续注册BeanDefinition
用于注册BeanDefinition的相关类
DefaultBeanDefinitionDocumentReader
doRegisterBeanDefinitions - 解析profile标签
protected void doRegisterBeanDefinitions(Element root) {
……
// 解析profile属性,判断当前环境是不是目标环境
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
// 如果不是目标环境,不再解析后面的标签了
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
……
return;
}
}
}
// 解析其他标签的主体部分
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
}该方法中首先判断了区分环境用的profile标签,然后进一步解析其他标签
parseBeanDefinitions - 解析默认/自定义标签框架
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
……
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}方法主体就是判断是不是默认命名空间,如果是按默认标签解析,不是的话解析自定义标签
public boolean isDefaultNamespace(@Nullable String namespaceUri) {
return !StringUtils.hasLength(namespaceUri) || BEANS_NAMESPACE_URI.equals(namespaceUri);
}判断标准就是是不是取的spring提供的beans规范的路径
public static final String BEANS_NAMESPACE_URI = "http://www.springframework.org/schema/beans";parseDefaultElement - 解析import、alias、bean、beans标签
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}方法框架比较简单,判断节点是哪一个,选择哪一个解析方法
processBeanDefinition - 解析bean标签
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}这块代码逻辑如下:
⾸先委托
BeanDefinitionDelegate#parseBeanDefinitionElement⽅法进⾏元素解析,返回BeanDefinitionHolder类型的实例bdHolder,经过这个⽅法后,bdHolder实例已经包含我们配置⽂件中配置的各种属性了,例如class、name、id、alias之类的属性。点我跳转当返回的bdHolder不为空的情况下若存在默认标签的⼦节点下再有⾃定义属性,还需要再次对⾃定义标签进⾏解析。
若返回的bdHolder不为空,检查下是否有一些自定义属性,
BeanDefinitionDelegate#decorateBeanDefinitionIfRequired装饰,点我跳转解析完成后,对解析后的bdHolder进⾏注册,同样,注册操作委托给了
BeanDefinitionReaderUtils#registerBeanDefinition⽅法,点我跳转最后发出响应事件fireComponentRegistered,通知相关的监听器,这个bean已经加载完成了。由调用方自行扩展并注册监听器。spring未提供任何默认处理流程
processAliasRegistration - 解析alias标签
解析name和alias两个核心属性,且必须要有,取到之后注册别名
protected void processAliasRegistration(Element ele) {
// 取name、alias两个属性
String name = ele.getAttribute(NAME_ATTRIBUTE);
String alias = ele.getAttribute(ALIAS_ATTRIBUTE);
……
// 注册别名
try {
getReaderContext().getRegistry().registerAlias(name, alias);
}
……
// 发送注册后事件监听
getReaderContext().fireAliasRegistered(name, alias, extractSource(ele));
……
}注册完之后同样是发事件监听,与bean标签类似,spring不提供默认处理,由调用方自行扩展
importBeanDefinitionResource - 解析import标签
protected void importBeanDefinitionResource(Element ele) {
// 1. 取location属性
String location = ele.getAttribute(RESOURCE_ATTRIBUTE);
if (!StringUtils.hasText(location)) {
getReaderContext().error("Resource location must not be empty", ele);
return;
}
// Resolve system properties: e.g. "${user.dir}"
location = getReaderContext().getEnvironment().resolveRequiredPlaceholders(location);
Set<Resource> actualResources = new LinkedHashSet<>(4);
// Discover whether the location is an absolute or relative URI
……第一步,是在校验resource属性,如果resource属性是系统属性(如${user.name:123}),创建一个占位符辅助器PropertyPlacehoderHelper,持有占位符的前缀${,后缀},值分隔符:信息,用于将${user.name:123}解析出属性名user.name以及默认值123,然后从PropertySources中获取user.name对应的属性值,如果没有就使用默认值。
boolean absoluteLocation = false;
try {
absoluteLocation = ResourcePatternUtils.isUrl(location) || ResourceUtils.toURI(location).isAbsolute();
}
// -- org.springframework.core.io.support.ResourcePatternUtils#isUrl --
public static boolean isUrl(@Nullable String resourceLocation) {
return (resourceLocation != null &&
(resourceLocation.startsWith(ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX) ||
ResourceUtils.isUrl(resourceLocation)));
}
// -- java.net.URI#isAbsolute --
public boolean isAbsolute() {
return scheme != null;
}第二步,判断resource属性值是一个url,或者是绝对路径
判断是url:以
classpath*:开头,或符合url的格式判断是绝对:有schema即为绝对
if (absoluteLocation) {
try {
int importCount = getReaderContext().getReader().loadBeanDefinitions(location, actualResources);
if (logger.isTraceEnabled()) {
logger.trace("Imported " + importCount + " bean definitions from URL location [" + location + "]");
}
}
……
}
else {
// No URL -> considering resource location as relative to the current file.
try {
int importCount;
Resource relativeResource = getReaderContext().getResource().createRelative(location);
if (relativeResource.exists()) {
importCount = getReaderContext().getReader().loadBeanDefinitions(relativeResource);
actualResources.add(relativeResource);
}
else {
String baseLocation = getReaderContext().getResource().getURL().toString();
importCount = getReaderContext().getReader().loadBeanDefinitions(
StringUtils.applyRelativePath(baseLocation, location), actualResources);
}第三步,分绝对路径和相对路径解析:
如果是绝对的,即定位到一个特定文件,根据路径继续解析里面的BeanDefintion,
如果是相对路径,若判断先计算绝对路径再解析
BeanDefinitionParserDelegate
BeanDefinitionHolder parseBeanDefinitionElement - 解析bean标签的id、name、alias属性
String id = ele.getAttribute(ID_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
List<String> aliases = new ArrayList<>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}这一部分根据属性解析id、name、aliases列表
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isTraceEnabled()) {
logger.trace("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}判定如果id为空,则beanName取别名第一个
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);这里取beanname要判断这个bean是不是已经存在过,没存在的话解析bean对应的标签。然后调用同名方法解析class和parent,这里解析出来就是bd了
if (beanDefinition != null) {
if (!StringUtils.hasText(beanName)) {
……
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}拿到bd后,封装返回,中间省略对beanName不存在的场景(id没有,别名也没有)的处理
AbstractBeanDefinition parseBeanDefinitionElement - 解析bean标签的class、parent、description属性
this.parseState.push(new BeanEntry(beanName));记录bean的解析状态
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}然后解析class和parent属性
try {
// 构造了一个通用的bd
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 开始解析属性
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
parseMetaElements(ele, bd);
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
parseConstructorArgElements(ele, bd);
parsePropertyElements(ele, bd);
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}然后首先构造一个genericBeanDefinition承载各类属性,然后解析各类属性,其中方法包括:
BeanDefinitionParserDelegate#createBeanDefinition:构造通用bd,跳转BeanDefinitionParserDelegate#parseBeanDefinitionAttributes:解析基础常用属性,包括singleton、scope、abstract、lazy-init、autowire、depends-on、autowire-candidate、primary、init-method、destroy-method、factory-method、factory-bean,跳转BeanDefinitionParserDelegate#parseMetaElements:解析meta属性,跳转BeanDefinitionParserDelegate#parseLookupOverrideSubElements:解析lookup-method属性,跳转BeanDefinitionParserDelegate#parseReplacedMethodSubElements:解析replaced-method属性,跳转BeanDefinitionParserDelegate#parseConstructorArgElements:解析constructor-arg属性,跳转BeanDefinitionParserDelegate#parsePropertyElements:解析property属性、子属性和值,跳转BeanDefinitionParserDelegate#parseQualifierElements:解析qualifier属性
createBeanDefinition - 构造通用bd
protected AbstractBeanDefinition createBeanDefinition(@Nullable String className, @Nullable String parentName)
throws ClassNotFoundException {
return BeanDefinitionReaderUtils.createBeanDefinition(
parentName, className, this.readerContext.getBeanClassLoader());
}BeanDefinition接口有三个实现:RootBeanDefinition、ChildBeanDefinition、GenericBeanDfinition,三种实现均继承了AbstractBeanDefinition。
BeanDefinition是
<bean>标签的java模型,定义了beanClass、scope、laziInit等属性和默认值RootBeanDefinition是⼀般性的
<bean>元素标签,GenericBeanDefinition是bean⽂件配置属性定义类,是⼀站式服务类。在配置⽂件中可以定义⽗
<bean>和⼦<bean>,⽗<bean>⽤RootBeanDefinition表⽰,⽽⼦<bean>⽤ChildBeanDefiniton表⽰,⽽没有⽗<bean>的<bean>就使⽤RootBeanDefinition表⽰。AbstractBeanDefinition对RootBeanDefinition和ChildBeanDefinition共同的类信息进⾏抽象。
public static AbstractBeanDefinition createBeanDefinition(
@Nullable String parentName, @Nullable String className, @Nullable ClassLoader classLoader) throws ClassNotFoundException {
GenericBeanDefinition bd = new GenericBeanDefinition();
bd.setParentName(parentName);
if (className != null) {
if (classLoader != null) {
bd.setBeanClass(ClassUtils.forName(className, classLoader));
}
else {
bd.setBeanClassName(className);
}
}
return bd;
}BeanDefinition承载的配置文件中的<bean>信息最终会注册到BeanDefinitionRegistry中,它就像Spring配置信息的内存数据库,主要是以map形式保存,后续操作将直接去BeanDefinitionRegistry中读取
parseBeanDefinitionAttributes - 解析基础常用属性
从document中获取的element中读取属性,存入beanDefinition中。被解析的属性包括:
singleton、scope、abstract、lazy-init、autowire、depends-on、autowire-candidate、primary、init-method、destroy-method、factory-method、factory-bean
public AbstractBeanDefinition parseBeanDefinitionAttributes(Element ele, String beanName,
@Nullable BeanDefinition containingBean, AbstractBeanDefinition bd) {
if (ele.hasAttribute(SINGLETON_ATTRIBUTE)) {
error("Old 1.x 'singleton' attribute in use - upgrade to 'scope' declaration", ele);
}
else if (ele.hasAttribute(SCOPE_ATTRIBUTE)) {
bd.setScope(ele.getAttribute(SCOPE_ATTRIBUTE));
}
else if (containingBean != null) {
// Take default from containing bean in case of an inner bean definition.
bd.setScope(containingBean.getScope());
}
if (ele.hasAttribute(ABSTRACT_ATTRIBUTE)) {
bd.setAbstract(TRUE_VALUE.equals(ele.getAttribute(ABSTRACT_ATTRIBUTE)));
}
String lazyInit = ele.getAttribute(LAZY_INIT_ATTRIBUTE);
if (isDefaultValue(lazyInit)) {
lazyInit = this.defaults.getLazyInit();
}
bd.setLazyInit(TRUE_VALUE.equals(lazyInit));
String autowire = ele.getAttribute(AUTOWIRE_ATTRIBUTE);
bd.setAutowireMode(getAutowireMode(autowire));
if (ele.hasAttribute(DEPENDS_ON_ATTRIBUTE)) {
String dependsOn = ele.getAttribute(DEPENDS_ON_ATTRIBUTE);
bd.setDependsOn(StringUtils.tokenizeToStringArray(dependsOn, MULTI_VALUE_ATTRIBUTE_DELIMITERS));
}
String autowireCandidate = ele.getAttribute(AUTOWIRE_CANDIDATE_ATTRIBUTE);
if (isDefaultValue(autowireCandidate)) {
String candidatePattern = this.defaults.getAutowireCandidates();
if (candidatePattern != null) {
String[] patterns = StringUtils.commaDelimitedListToStringArray(candidatePattern);
bd.setAutowireCandidate(PatternMatchUtils.simpleMatch(patterns, beanName));
}
}
else {
bd.setAutowireCandidate(TRUE_VALUE.equals(autowireCandidate));
}
if (ele.hasAttribute(PRIMARY_ATTRIBUTE)) {
bd.setPrimary(TRUE_VALUE.equals(ele.getAttribute(PRIMARY_ATTRIBUTE)));
}
if (ele.hasAttribute(INIT_METHOD_ATTRIBUTE)) {
String initMethodName = ele.getAttribute(INIT_METHOD_ATTRIBUTE);
bd.setInitMethodName(initMethodName);
}
else if (this.defaults.getInitMethod() != null) {
bd.setInitMethodName(this.defaults.getInitMethod());
bd.setEnforceInitMethod(false);
}
if (ele.hasAttribute(DESTROY_METHOD_ATTRIBUTE)) {
String destroyMethodName = ele.getAttribute(DESTROY_METHOD_ATTRIBUTE);
bd.setDestroyMethodName(destroyMethodName);
}
else if (this.defaults.getDestroyMethod() != null) {
bd.setDestroyMethodName(this.defaults.getDestroyMethod());
bd.setEnforceDestroyMethod(false);
}
if (ele.hasAttribute(FACTORY_METHOD_ATTRIBUTE)) {
bd.setFactoryMethodName(ele.getAttribute(FACTORY_METHOD_ATTRIBUTE));
}
if (ele.hasAttribute(FACTORY_BEAN_ATTRIBUTE)) {
bd.setFactoryBeanName(ele.getAttribute(FACTORY_BEAN_ATTRIBUTE));
}
return bd;
}根据代码可以看出这里是只存不用的
parseMetaElements - 解析meta属性
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (isCandidateElement(node) && nodeNameEquals(node, META_ELEMENT)) {
Element metaElement = (Element) node;
String key = metaElement.getAttribute(KEY_ATTRIBUTE);
String value = metaElement.getAttribute(VALUE_ATTRIBUTE);
BeanMetadataAttribute attribute = new BeanMetadataAttribute(key, value);
attribute.setSource(extractSource(metaElement));
attributeAccessor.addMetadataAttribute(attribute);
}
}循环子节点
meta没有自己的字段,直接塞到attribute里面
parseLookupOverrideSubElements - 解析lookup-method
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (isCandidateElement(node) && nodeNameEquals(node, LOOKUP_METHOD_ELEMENT)) {
Element ele = (Element) node;
String methodName = ele.getAttribute(NAME_ATTRIBUTE);
String beanRef = ele.getAttribute(BEAN_ELEMENT);
LookupOverride override = new LookupOverride(methodName, beanRef);
override.setSource(extractSource(ele));
overrides.addOverride(override);
}
}循环子节点
解析流程和meta属性差不多,解析结果存放在BeanDefinitoin的methodOverrides属性中
parseReplacedMethodSubElements
逻辑和上面差不多,解析了replaced-method属性和replacer、arg-type子标签,存放在BeanDefinitoin的methodOverrides属性中
parseConstructorArgElements- 解析constructor-arg
构造函数解析较为复杂,因为它有子元素的概念。并且允许有多个入参。因此bean元素下面的constructor-arg要循环解析。
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (isCandidateElement(node) && nodeNameEquals(node, CONSTRUCTOR_ARG_ELEMENT)) {
parseConstructorArgElement((Element) node, bd);
}
}具体解析流程封装在parseConstructorArgElement方法
String indexAttr = ele.getAttribute(INDEX_ATTRIBUTE);
String typeAttr = ele.getAttribute(TYPE_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);可以看到首先先取了index、type、name三个属性
if (StringUtils.hasLength(indexAttr)) {
……
int index = Integer.parseInt(indexAttr);
……
Object value = parsePropertyValue(ele, bd, null);
ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);
……
bd.getConstructorArgumentValues().addIndexedArgumentValue(index, valueHolder);如果带了index属性,用ValueHolder承接解析出来的子属性,存到AbstractBeanDefinition中的constructorArgumentValues的indexedArugmentValue中
else {
……
bd.getConstructorArgumentValues().addGenericArgumentValue(valueHolder);
}如果不带index属性解析出来存到AbstractBeanDefinition中的constructorArgumentValues的GenericArgumentValue中
Object value = parsePropertyValue(ele, bd, null);解析子属性调用的是BeanDefinitionParserDelegate#parsePropertyValue方法,点我跳转
parsePropertyElements - 解析property属性
直接跳转到下级方法
// 取属性名称
String propertyName = ele.getAttribute(NAME_ATTRIBUTE);
……
try {
if (bd.getPropertyValues().contains(propertyName)) {
error("Multiple 'property' definitions for property '" + propertyName + "'", ele);
return;
}
// 解析属性值
Object val = parsePropertyValue(ele, bd, propertyName);
PropertyValue pv = new PropertyValue(propertyName, val);
// 子元素中还有可以有meta属性,继续解析
parseMetaElements(ele, pv);
pv.setSource(extractSource(ele));
bd.getPropertyValues().addPropertyValue(pv);
}解析完成后存储在BD中的MutablePropertyValues属性中
private MutablePropertyValues propertyValues;parsePropertyValue - 解析属性值
构造函数标签和property标签如果有属性和值,基于此方法进行解析。
类型限制:ref、value、子元素一种,discription和meta不处理。
// Should only have one child element: ref, value, list, etc.
NodeList nl = ele.getChildNodes();
Element subElement = null;
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element && !nodeNameEquals(node, DESCRIPTION_ELEMENT) &&
!nodeNameEquals(node, META_ELEMENT)) {
// Child element is what we're looking for.
if (subElement != null) {
error(elementName + " must not contain more than one sub-element", ele);
}
else {
subElement = (Element) node;
}
}
}这一部分是在获取子元素
对于子元素的形式,可以参考下面案例,就是property元素不直接使用ref、value属性,而是使用集合类型的子元素注入的形式。
boolean hasRefAttribute = ele.hasAttribute(REF_ATTRIBUTE);
boolean hasValueAttribute = ele.hasAttribute(VALUE_ATTRIBUTE);
if ((hasRefAttribute && hasValueAttribute) ||
((hasRefAttribute || hasValueAttribute) && subElement != null)) {
error(elementName +
" is only allowed to contain either 'ref' attribute OR 'value' attribute OR sub-element", ele);
}这部分做了一个判断:只允许是ref、value、子元素中的一种,不能有两种或两种以上
if (hasRefAttribute) {
String refName = ele.getAttribute(REF_ATTRIBUTE);
if (!StringUtils.hasText(refName)) {
error(elementName + " contains empty 'ref' attribute", ele);
}
RuntimeBeanReference ref = new RuntimeBeanReference(refName);
ref.setSource(extractSource(ele));
return ref;
}这一部分判断是ref形式,则使用RuntimeBeanReference封装ref属性
else if (hasValueAttribute) {
TypedStringValue valueHolder = new TypedStringValue(ele.getAttribute(VALUE_ATTRIBUTE));
valueHolder.setSource(extractSource(ele));
return valueHolder;
}这一部分轮到value属性了,对于value属性,使用TypedStringValue封装
else if (subElement != null) {
return parsePropertySubElement(subElement, bd);
}最后是子元素场景,这一部分调用新方法BeanDefinitionParserDelegate#parsePropertySubElement 解析,见下面parsePropertySubElement
parsePropertySubElement - 解析子元素
一个元素的子元素就是ref、value、idref、bean、或者集合类型,xml写法参考下面案例:
可以看到数组元素的子元素最常用的ref、value、bean几种,以及数组本身就是<property>元素的集合类型子元素。
if (!isDefaultNamespace(ele)) {
return parseNestedCustomElement(ele, bd);
}上来首先判断子元素的命名空间,如果子元素不是默认命名空间,则执行解析自定义的逻辑,见parseNestedCustomElement方法
private BeanDefinitionHolder parseNestedCustomElement(Element ele, @Nullable BeanDefinition containingBd) {
BeanDefinition innerDefinition = parseCustomElement(ele, containingBd);
if (innerDefinition == null) {
error("Incorrect usage of element '" + ele.getNodeName() + "' in a nested manner. " +
"This tag cannot be used nested inside <property>.", ele);
return null;
}
String id = ele.getNodeName() + BeanDefinitionReaderUtils.GENERATED_BEAN_NAME_SEPARATOR +
ObjectUtils.getIdentityHexString(innerDefinition);
if (logger.isTraceEnabled()) {
logger.trace("Using generated bean name [" + id +
"] for nested custom element '" + ele.getNodeName() + "'");
}
return new BeanDefinitionHolder(innerDefinition, id);
}核心其实是在parsecustomelement
如果子元素是bean,则按照解析bean的流程继续解析。
else if (nodeNameEquals(ele, BEAN_ELEMENT)) {
BeanDefinitionHolder nestedBd = parseBeanDefinitionElement(ele, bd);
if (nestedBd != null) {
nestedBd = decorateBeanDefinitionIfRequired(ele, nestedBd, bd);
}
return nestedBd;
}这一部分,如果子元素是bean类型,则按照解析<bean>标签的流程再走一遍,见parseBeanDefinitionElement方法
else if (nodeNameEquals(ele, REF_ELEMENT)) {
……
RuntimeBeanReference ref = new RuntimeBeanReference(refName, toParent);
ref.setSource(extractSource(ele));
return ref;
}如果子元素是ref,取bean和parent属性做对比,如果一致,通过bool类型存入RuntimeBeanReference。
else if (nodeNameEquals(ele, IDREF_ELEMENT)) {
return parseIdRefElement(ele);
}如果子元素是idref标签,对应解析
else if (nodeNameEquals(ele, VALUE_ELEMENT)) {
return parseValueElement(ele, defaultValueType);
}如果子元素是value标签,对应解析,看parseValueElement方法
else if (nodeNameEquals(ele, ARRAY_ELEMENT)) {
return parseArrayElement(ele, bd);
}如果子元素是array标签,对应解析,看parseArrayElement方法
else if (nodeNameEquals(ele, LIST_ELEMENT)) {
return parseListElement(ele, bd);
}如果子元素是list标签,对应解析,看parseListElement方法
else if (nodeNameEquals(ele, SET_ELEMENT)) {
return parseSetElement(ele, bd);
}如果子元素是set标签,对应解析,看parseSetElement方法
else if (nodeNameEquals(ele, MAP_ELEMENT)) {
return parseMapElement(ele, bd);
}如果子元素是map标签,对应解析,看parseMapElement方法
else if (nodeNameEquals(ele, PROPS_ELEMENT)) {
return parsePropsElement(ele);
}如果子元素是props标签,对应解析,看parsePropsElement方法
parseValueElement - 解析value子标签
public Object parseValueElement(Element ele, @Nullable String defaultTypeName) {
// It's a literal value.
String value = DomUtils.getTextValue(ele);
String specifiedTypeName = ele.getAttribute(TYPE_ATTRIBUTE);
String typeName = specifiedTypeName;
// 如果没指定type类型,使用默认type
if (!StringUtils.hasText(typeName)) {
typeName = defaultTypeName;
}
try {
// 指定type类型,则构造对应type的值
TypedStringValue typedValue = buildTypedStringValue(value, typeName);
typedValue.setSource(extractSource(ele));
typedValue.setSpecifiedTypeName(specifiedTypeName);
return typedValue;
}
catch (ClassNotFoundException ex) {
error("Type class [" + typeName + "] not found for <value> element", ele, ex);
return value;
}
}核心是这个buildTypedStringValue方法
protected TypedStringValue buildTypedStringValue(String value, @Nullable String targetTypeName)
throws ClassNotFoundException {
ClassLoader classLoader = this.readerContext.getBeanClassLoader();
TypedStringValue typedValue;
if (!StringUtils.hasText(targetTypeName)) {
typedValue = new TypedStringValue(value);
}
else if (classLoader != null) {
// 反射构造
Class<?> targetType = ClassUtils.forName(targetTypeName, classLoader);
typedValue = new TypedStringValue(value, targetType);
}
else {
typedValue = new TypedStringValue(value, targetTypeName);
}
return typedValue;
}利用反射,构建出type的Class,如果type是基本类型,或者 java.lang 包下的常用类,可以直接从缓存(primitiveTypeNameMap、commonClassCache)中获取
parseArrayElement/parseListElement/parseSetElement - array/list/set解析
这三个逻辑是基本一致的,以Array参考
String elementType = arrayEle.getAttribute(VALUE_TYPE_ATTRIBUTE);
NodeList nl = arrayEle.getChildNodes();
ManagedArray target = new ManagedArray(elementType, nl.getLength());
target.setSource(extractSource(arrayEle));
target.setElementTypeName(elementType);
// 解析merge属性
target.setMergeEnabled(parseMergeAttribute(arrayEle));
parseCollectionElements(nl, target, bd, elementType);可以看到上来先找value-type属性,找不到默认为String
解析出来的array存到ManagedArray中,然后从array里面解析merge属性,merge属性可以让子类重写的属性不再覆盖父类,而是在父类的基础上补充。方法参考parseMergeAttribute
public boolean parseMergeAttribute(Element collectionElement) {
String value = collectionElement.getAttribute(MERGE_ATTRIBUTE);
if (isDefaultValue(value)) {
value = this.defaults.getMerge();
}
return TRUE_VALUE.equals(value);
}这里也是MergedBeanDefinition加载的点,在refresh流程里面也有介绍
最后调用parseCollectionElemets方法解析数组中的元素。
for (int i = 0; i < elementNodes.getLength(); i++) {
Node node = elementNodes.item(i);
if (node instanceof Element && !nodeNameEquals(node, DESCRIPTION_ELEMENT)) {
target.add(parsePropertySubElement((Element) node, bd, defaultElementType));
}
}如果又有子元素,通过循环的形式取解析,只要不是discription的,就调用解析子元素方法循环解析,见parsePropertySubElement方法
parseMapElement - map解析
因为map有k、v,因此对于value-type的解析有两种
String defaultKeyType = mapEle.getAttribute(KEY_TYPE_ATTRIBUTE);
String defaultValueType = mapEle.getAttribute(VALUE_TYPE_ATTRIBUTE);批量找到所有的entry标签,做for循环依次解析,先解析entry下面还有子元素的场景:
for (int j = 0; j < entrySubNodes.getLength(); j++) {
…………
if (nodeNameEquals(candidateEle, KEY_ELEMENT)) {
…………
keyEle = candidateEle;
…………
}
else {
// Child element is what we're looking for.
if (nodeNameEquals(candidateEle, DESCRIPTION_ELEMENT)) {
// the element is a <description> -> ignore it
}
…………
else {
valueEle = candidateEle;
}
}
}
}可以看到循环过程中依次判断元素name是key、还是description、还是value,description不处理,key和value分别存入keyEle和valueEle。
然后处理entry标签中的key属性和key-ref属性,要求:
不能同时有key和key-ref属性
有key或key-ref属性的时候不允许有key子标签,即keyEle为空
if (hasKeyAttribute) {
// 解析key值
key = buildTypedStringValueForMap(entryEle.getAttribute(KEY_ATTRIBUTE), defaultKeyType, entryEle);
}
-----------------------
protected final Object buildTypedStringValueForMap(String value, String defaultTypeName, Element entryEle) {
try {
TypedStringValue typedValue = buildTypedStringValue(value, defaultTypeName);如果有key属性,调用buildTypedStringValueForMap处理后存入TypeStringValueForMap,逻辑和array的也是类似的
else if (hasKeyRefAttribute) {
String refName = entryEle.getAttribute(KEY_REF_ATTRIBUTE);
if (!StringUtils.hasText(refName)) {
error("<entry> element contains empty 'key-ref' attribute", entryEle);
}
RuntimeBeanReference ref = new RuntimeBeanReference(refName);
ref.setSource(extractSource(entryEle));
key = ref;
}如果有key-ref属性处理后存入RuntimeBeanReference
else if (keyEle != null) {
key = parseKeyElement(keyEle, bd, defaultKeyType);
}
---------------------------------
protected Object parseKeyElement(Element keyEle, @Nullable BeanDefinition bd, String defaultKeyTypeName) {
……
return parsePropertySubElement(subElement, bd, defaultKeyTypeName);
}没有key和key-ref则调用parseKeyElement方法解析子元素,里面也是遍历子元素,然后调用解析子元素方法进一步解析,见parsePropertySubElement
对于value的解析与上面对key的解析完全一致,不再额外赘述。
// Add final key and value to the Map.
map.put(key, value);解析完的key、value调用Map::put方法存入map
parsePropsElement - 解析props子元素
props解析就比较简单,先遍历所有的prop子元素,对每个prop解析出key属性对应的key值,然后分割value属性,存入TypeStringValue
public Properties parsePropsElement(Element propsEle) {
ManagedProperties props = new ManagedProperties();
props.setSource(extractSource(propsEle));
props.setMergeEnabled(parseMergeAttribute(propsEle));
// 找所有的props标签,都是已经封装好的方法
List<Element> propEles = DomUtils.getChildElementsByTagName(propsEle, PROP_ELEMENT);
// 遍历每个props
for (Element propEle : propEles) {
// 找key
String key = propEle.getAttribute(KEY_ATTRIBUTE);
// 找value
String value = DomUtils.getTextValue(propEle).trim();
TypedStringValue keyHolder = new TypedStringValue(key);
keyHolder.setSource(extractSource(propEle));
TypedStringValue valueHolder = new TypedStringValue(value);
valueHolder.setSource(extractSource(propEle));
// 存储
props.put(keyHolder, valueHolder);
}
return props;
}decorateBeanDefinitionIfRequired - 解析自定义标签和属性用于装饰bean标签
这里要和BeanDefinitionParserDelegate#parseCustomElement区分开,parseCustomElememts(点我跳转)是解析一套自定义schema的,例如mybatis的加载模式(点我跳转),而decorateBeanDefinitionIfRequired是用于解析自定义标签和属性用于装饰<bean>标签的
内部调用同名方法。第三个参数containBd是BeanDefinition对象。这个参数传到最先是用来构造返回值的
public BeanDefinitionHolder decorateBeanDefinitionIfRequired(Element ele,
BeanDefinitionHolder originalDef) {
return decorateBeanDefinitionIfRequired(ele, originalDef, null);
}第三个参数containBd是BeanDefinition对象。这个参数传到最先是用来构造返回值的,可以先看下最下层的方法:
public BeanDefinitionHolder decorateIfRequired(
Node node, BeanDefinitionHolder originalDef, @Nullable BeanDefinition containingBd) {
……
// 返回值构造
BeanDefinitionHolder decorated =
handler.decorate(node, originalDef, new ParserContext(this.readerContext, this, containingBd));
……
}这里为了使⽤⽗类的scope属性,以备⼦类若没有设置scope时默认使⽤⽗类的属性,这⾥分析的是顶层配置,所以传递null
再回来看方法体:
// Decorate based on custom attributes first.
NamedNodeMap attributes = ele.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node node = attributes.item(i);
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
// Decorate based on custom nested elements.
NodeList children = ele.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node node = children.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
}然后对于自定义的属性和标签两种,分别调用decorateIfRequired装饰
if (namespaceUri != null && !isDefaultNamespace(namespaceUri)) {
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler != null) {
BeanDefinitionHolder decorated =
handler.decorate(node, originalDef, new ParserContext(this.readerContext, this, containingBd));
if (decorated != null) {
return decorated;
}
}这部分是根据namespace获取对于的命名空间解析器handler,然后调用自定义的NamespaceHandler#decorate方法解析标签和属性
else if (namespaceUri.startsWith("http://www.springframework.org/schema/")) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", node);
}如果发现是默认的空间,报个错
parseCustomElement
public BeanDefinition parseCustomElement(Element ele, @Nullable BeanDefinition containingBd) {
// 1. 获取命名空间
String namespaceUri = getNamespaceURI(ele);
if (namespaceUri == null) {
return null;
}
// 2. 根据命名空间找对应的NameSpaceHandler
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
// 3. 调用自定义handler的parse方法
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}这里一共三个步骤:
获取命名空间,其中获取命名空间是委托dom处理的,暂不深入分析
根据命名空间找到对应的NameSpaceHandler,首先调用
XmlReaderContext#getNamespaceHandlerResolver方法,点我跳转,获取NamespaceHandlerResolver,然后调用resolve方法根据namespaceuri解析对应的handler,点我跳转调用自定义的
NameSpaceHandler#parse方法解析,点我跳转
BD注册相关类
BeanDefinitionReaderUtils
registerBeanDefinition - 注册bean入口
在DefaultBeanDefinitionDocumentReader#processBeanDefinition方法解析bean标签,每个bean标签就是一个待注册的bean,加载成BeanDefinitionHolder进行注册,调用BeanDefinitionReaderUtils#registerBeanDefinition,参考DefaultBeanDefinitionDocumentReader
public static void registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// 1. 注册bd
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// 2. 注册别名
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}入参中的BeanDefinitionRegistry是提供bean注册能力的接口,正常情况下默认实现就是DefaultListableBeanFactory,参考以下:
这个方法可以分成两个步骤:
注册bean,调用
DefaultListableBeanFactory#registerBeanDefinition,点我跳转注册别名,调用
SimpleAliasRegistry#registerAlias,点我跳转
DefaultListableBeanFactory
registerBeanDefinition - 注册bean核心方法
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}第一步:校验bd的合法性,校验的是bd本身,而非xml配置文件的合法性,调用AbstractBeanDefinition#validate方法,点我跳转
BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);
if (existingDefinition != null) {
// map中已存在这个bean,对应处理
……
}
else {
// map中不存在这个bean,对应处理
……
}第二步是从内存缓存中获取这个bean,分别对已存在和未存在两种情况做处理
先看已存在
if (existingDefinition != null) {
// 判断是否允许覆盖
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionOverrideException(beanName, beanDefinition, existingDefinition);
}
// 判断bean角色定义
else if (existingDefinition.getRole() < beanDefinition.getRole()) {
logger.info……
}
// 判断 BeanDefinition 属性值不等于原 BeanDefinition
else if (!beanDefinition.equals(existingDefinition)) {
logger.debug……
}
// 其他场景
else {
logger.trace……
}
this.beanDefinitionMap.put(beanName, beanDefinition);
}这里有五个场景:
是否允许覆盖,不允许抛异常
判断bean角色,当原 BeanDefinition 角色小于新的 BeanDefinition 角色时,输出一个 warn 日志,提示 BeanDefinition 被覆盖
0:用户定义的 Bean
1:来源于配置文件的 Bean
2:Spring 内部的 Bean
判断新bean值不等于原bean
其他场景
可以看到这五个场景除了不允许覆盖的场景抛异常,其他场景都是直接覆盖,因此可知注册name相同的bean将会导致bean被覆盖
然后看beanDefinition不存在的场景:
else {
// bean已开始创建
if (hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
synchronized (this.beanDefinitionMap) {
// 将 Bean 对应的 BeanDefinition 放入 beanDefinitionMap 中
this.beanDefinitionMap.put(beanName, beanDefinition);
// 创建新的 beanNames 集合,并将已缓存的 beanName 和新的 beanName 加入该集合
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
removeManualSingletonName(beanName);
}
}
// bean尚处在注册阶段
else {
// 将当前 Bean 对应的 BeanDefinition 放入 beanDefinitionMap 中
this.beanDefinitionMap.put(beanName, beanDefinition);
// 将当前 beanName 放入 beanDefinitionNames
this.beanDefinitionNames.add(beanName);
removeManualSingletonName(beanName);
}
// 将存储冻结 BeanDefinition 的 Map 置为 null
this.frozenBeanDefinitionNames = null;
}这里可以看到是两个场景:
bean已经开始创建的话,需要sychronized锁,将 Bean 对应的 BeanDefinition 放入 beanDefinitionMap 中
bean还处于注册阶段,存入即可
if (existingDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}最后如果bean是单例,且已经存在,这里还要调用resetBeanDefinition做一些单例bean的清理工作
getBeanDefinition - 获取bd的能力
DefaultListableBeanFactory还实现了BeanDefinitionRegistry#getBeanDefinition ,从而获取bd
public BeanDefinition getBeanDefinition(String beanName) throws NoSuchBeanDefinitionException {
BeanDefinition bd = this.beanDefinitionMap.get(beanName);
if (bd == null) {
if (logger.isTraceEnabled()) {
logger.trace("No bean named '" + beanName + "' found in " + this);
}
throw new NoSuchBeanDefinitionException(beanName);
}
return bd;
}可以看出来,逻辑就是从刚刚构造bean存放的内存缓存里面取
BeanDefinition - bean定义
XML文档解析生成的最终产物是GenericBeanDefinition,它继承自AbstractBeanDefinition。当然抽象父类保留了bean的大部分通用属性。
BeanDefinition的核心属性
// bean的作⽤范围,对应bean属性scope
private String scope = SCOPE_DEFAULT;
// 是否是单例,来⾃bean属性scope
private boolean singleton = true;
// 是否是原型,来⾃bean属性scope
private boolean prototype = false;
// 是否是抽象,对应bean属性abstract
private boolean abstractFlag = false;
// 是否延迟加载,对应bean属性lazy-init
private boolean lazyInit = false;
// ⾃动注⼊模式,对应bean属性autowire
private int autowireMode = AUTOWIRE_NO;
// 依赖检查,Spring 3.0后弃⽤这个属性
private int dependencyCheck = DEPENDENCY_CHECK_NONE;
// ⽤来表⽰⼀个bean的实例化依靠另⼀个bean先实例化,对应bean属性depend-on
private String[] dependsOn;
// autowire-candidate属性设置为false,这样容器在查找⾃动装配对象时,将不考虑该bean,即它不会被考//虑作为其他bean⾃动装配的候选者,但是该bean本⾝还是可以使⽤⾃动装配来注⼊其他bean的。对应bean属性autowire-candidate
private boolean autowireCandidate = true;
// ⾃动装配时当出现多个bean候选者时,将作为⾸选者,对应bean属性primary
private boolean primary = false;
// ⽤于记录Qualifier,对应⼦元素qualifier
private final Map<String, AutowireCandidateQualifier> qualifiers = new LinkedHashMap<String,AutowireCandidateQualifier>(0);
// 允许访问⾮公开的构造器和⽅法,程序设置
private boolean nonPublicAccessAllowed = true;
// 是否以⼀种宽松的模式解析构造函数,默认为true,如果为false,则在如下情况
* interface ITest{}
* class ITestImpl implements ITest{};
* class Main{
* Main(ITest i){}
* Main(ITestImpl i){}
* }
* 抛出异常,因为Spring⽆法准确定位哪个构造函数
* 程序设置
*/
private boolean lenientConstructorResolution = true;
// 记录构造函数注⼊属性,对应bean属性constructor-arg
private ConstructorArgumentValues constructorArgumentValues;
// 普通属性集合
private MutablePropertyValues propertyValues;
// ⽅法重写的持有者 ,记录lookup-method、replaced-method元素
private MethodOverrides methodOverrides = new MethodOverrides();
// 对应bean属性factory-bean,⽤法:
* <bean id="instanceFactoryBean"
class="example.chapter3.InstanceFactoryBean"/>
* <bean id="currentTime" factorybean="instanceFactoryBean" factory-method="
createTime"/>
private String factoryBeanName;
// 对应bean属性factory-method
private String factoryMethodName;
// 初始化⽅法,对应bean属性init-method
private String initMethodName;
// 销毁⽅法,对应bean属性destory-method
private String destroyMethodName;
// 是否执⾏init-method,程序设置
private boolean enforceInitMethod = true;
// 是否执⾏destory-method,程序设置
private boolean enforceDestroyMethod = true;
// 是否是⽤户定义的⽽不是应⽤程序本⾝定义的,创建AOP时候为true,程序设置
private boolean synthetic = false;
// 定义这个bean的应⽤ ,APPLICATION:⽤户,INFRASTRUCTURE:完
全内部使⽤,与⽤户⽆关,SUPPORT:某些复杂配置的⼀部分程序设置
private int role = BeanDefinition.ROLE_APPLICATION;
// bean的描述信息
private String description;
// 这个bean定义的资源
private Resource resource;
validate - 校验bd合法性
public void validate() throws BeanDefinitionValidationException {
if (hasMethodOverrides() && getFactoryMethodName() != null) {
throw new BeanDefinitionValidationException(
"Cannot combine factory method with container-generated method overrides: " +
"the factory method must create the concrete bean instance.");
}
继承自AbstractBeanDefinition
校验methodOverrides是否与⼯⼚⽅法并存或者methodOverrides对应的⽅法根本不存在
if (hasBeanClass()) {
prepareMethodOverrides();
}如果bean的类型是java.lang.Class类的对象(即反射的类对象),还要针对overrides方法进行处理
prepareMethodOverrides/prepareMethodOverride - 处理重载方法
public void prepareMethodOverrides() throws BeanDefinitionValidationException {
// Check that lookup methods exist and determine their overloaded status.
if (hasMethodOverrides()) {
getMethodOverrides().getOverrides().forEach(this::prepareMethodOverride);
}
}找到所有的重载方法,这里是根据@override标签找的,找到后依次解析:
protected void prepareMethodOverride(MethodOverride mo) throws BeanDefinitionValidationException {
int count = ClassUtils.getMethodCountForName(getBeanClass(), mo.getMethodName());
// 如果没有找到需要重写的方法,抛异常
if (count == 0) {
throw new BeanDefinitionValidationException(
"Invalid method override: no method with name '" + mo.getMethodName() +
"' on class [" + getBeanClassName() + "]");
}
else if (count == 1) {
// 数量为1说明没重载
mo.setOverloaded(false);
}
}在prepareMethodOverrides方法中找所有带重写的方法,找同名方法,如果只有一个方法,说明没有方法重载,也不需要校验
这里先获取override标注的方法个数,标记MethodOverride暂未被覆盖,目的是为了避免参数类型检查开销。
这组方法的目的实际上是处理Spring中配置的lookup-method合replace-method,这两个配置加载出来就是放在BeanDefinition的methodOverrides。而后续的处理是通过拦截器在bean实例化之前拦截做增强处理。
SimpleAliasRegistry
registerAlias
name是beanId,alias是别名,实际上就是成对存入aliasMap
第一步:如果别名与name相同,抛弃该别名
synchronized (this.aliasMap) {
if (alias.equals(name)) {
this.aliasMap.remove(alias);
……
别名的注册是通过synchronized进行同步锁的
首先如果别名和name一致,则抛弃别名
else {
String registeredName = this.aliasMap.get(alias);
if (registeredName != null) {
if (registeredName.equals(name)) {
// An existing alias - no need to re-register
return;
}
if (!allowAliasOverriding()) {
throw new IllegalStateException("Cannot define alias '" + alias + "' for name '" +
name + "': It is already registered for name '" + registeredName + "'.");
}获取别名的map看看该别名是不是已经有注册过了,如果注册过,会看下用户的覆盖配置是否允许覆盖。
checkForAliasCircle(name, alias);
this.aliasMap.put(alias, name);检查别名循环调用,即当A->B存在时,若再次出现A->C->B时候则会抛出异常,最后注册到map中
自定义标签解析相关类
自定义标签解析是如何实现的
创建一个需要扩展的组件
定义一个XSD文件描述组件内容
创建一个文件,实现BeanDefinitionParser接口,⽤来解析XSD⽂件中的定义和组件定义。
创建⼀个Handler⽂件,扩展⾃NamespaceHandlerSupport,⽬的是将组件注册到Spring容器。
编写Spring.handlers和Spring.schemas⽂件
以下案例:
假如有一个User pojo
package test.customtag;
public class User {
private String userName;
private String email;
//省略set/get⽅法
}定义xsd文件
<?xml version="1.0" encoding="UTF-8"?>
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.lexueba.com/schema/user"
xmlns:tns="http://www.lexueba.com/schema/user"
elementFormDefault="qualified">
<element name="user">
<complexType>
<attribute name="id" type="string"/>
<attribute name="userName" type="string"/>
<attribute name="email" type="string"/>
</complexType>
</element>
</schema>包含一个新的命名空间targetNamespace
定义了一个name为user的标签,标签有id、userName、email三个属性,类型为string
实现BeanDefinitionParser接口
public class UserBeanDefinitionParser extends AbstractSingleBeanDefinitionParser {
/**
* Element对应的类
*/
protected Class getBeanClass(Element element) {
return User.class;
}
/**
* 从element中解析并提取对应的元素
*/
protected void doParse(Element element, BeanDefinitionBuilder bean) {
String userName = element.getAttribute("userName");
String email = element.getAttribute("email");
//将提取的数据放⼊到BeanDefinitionBuilder中
//待到完成所有bean的解析后统⼀注册到beanFactory中
if (StringUtils.hasText(userName)) {
bean.addPropertyValue("userName", userName);
}
if (StringUtils.hasText(email)) {
bean.addPropertyValue("email", email);
}
}
}实现BeanDefifnitionParser#doParse方法是⽤来解析XSD⽂件中的定义和组件定义
重写NamespaceHandlerSupport
public class MyNamespaceHandler extends NamespaceHandlerSupport {
public void init() {
registerBeanDefinitionParser("user", newUserBeanDefinitionParser());
}
}至此,遇到<user:aaa这样的标签,就会把元素丢给UserBeanDefinitionParser去解析
编写Spring.handlers和Spring.schemas文件
默认位置是在⼯程的/META-INF/⽂件夹下,也可以通过Spring的扩展或者修改源码的⽅式改变路径
// Spring.handlers
http\://www.lexueba.com/schema/user=test.customtag.MyNamespaceHandler
// Spring.shcemas
http\://www.lexueba.com/schema/user.xsd=META-INF/Spring-test.xsd编写xsd配置文件测试
<beans xmlns="http://www.Springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:myname="http://www.lexueba.com/schema/user"
xsi:schemaLocation="http://www.Springframework.org/schema/beans
http://www. Springframework.org/schema/beans/Spring-beans-2.0.xsd
http://www.lexueba.com/schema/user
http://www.lexueba.com/schema/user.xsd">
<myname:user id="testbean" userName="aaa" email="bbb"/>
</beans>myname:user即上面引入的xml命名空间myname,调用了其中的user标签
XmlReaderContext
分析namespaceHandlerResolver是怎么来的
public final NamespaceHandlerResolver getNamespaceHandlerResolver() {
return this.namespaceHandlerResolver;
}首先取的是自己的成员变量
public XmlReaderContext(
Resource resource, ProblemReporter problemReporter,
ReaderEventListener eventListener, SourceExtractor sourceExtractor,
XmlBeanDefinitionReader reader, NamespaceHandlerResolver namespaceHandlerResolver) {
super(resource, problemReporter, eventListener, sourceExtractor);
this.reader = reader;
this.namespaceHandlerResolver = namespaceHandlerResolver;
}在构造函数里面赋值
public XmlReaderContext createReaderContext(Resource resource) {
return new XmlReaderContext(resource, this.problemReporter, this.eventListener,
this.sourceExtractor, this, getNamespaceHandlerResolver());
}构造函数只有一处调用,是在XmlBeanDefinitionReader#createReaderContext 而这里传的值又是XmlBeanDefinitionReader#getNamespaceHandlerResolver 来的
public NamespaceHandlerResolver getNamespaceHandlerResolver() {
if (this.namespaceHandlerResolver == null) {
this.namespaceHandlerResolver = createDefaultNamespaceHandlerResolver();
}
return this.namespaceHandlerResolver;
}protected NamespaceHandlerResolver createDefaultNamespaceHandlerResolver() {
ResourceLoader resourceLoader = getResourceLoader();
ClassLoader cl = (resourceLoader != null ? resourceLoader.getClassLoader() : getBeanClassLoader());
return new DefaultNamespaceHandlerResolver(cl);
}到这里可以看到是构造的DefaultNamespaceHandlerResolver
DefaultNamespaceHandlerResolver
resolve - 根据namespaceuri解析对应的handler
首先加载所有的在spring.handlers中实现的解析器
Map<String, Object> handlerMappings = getHandlerMappings();
Object handlerOrClassName = handlerMappings.get(namespaceUri);
if (handlerOrClassName == null) {
return null;
}
else if (handlerOrClassName instanceof NamespaceHandler) {
return (NamespaceHandler) handlerOrClassName;
}获取handlerMapping,点我跳转
try {
Class<?> handlerClass = ClassUtils.forName(className, this.classLoader);
if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) {
throw new FatalBeanException("Class [" + className + "] for namespace [" + namespaceUri +
"] does not implement the [" + NamespaceHandler.class.getName() + "] interface");
}
NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);
// 初始化操作
namespaceHandler.init();
handlerMappings.put(namespaceUri, namespaceHandler);
return namespaceHandler;
}上面拿到className后,通过反射构造NamespaceHandler的实例
这里执行了一个NamespaceHandler#init初始化操作,是为了进行BeanDefinitionParser的注册。
在这⾥,可以注册多个标签解析器,如<myname:A、<myname:B等,使得自定义的命名空间中可以⽀持多种标签解析。
此处是要给调用方自行实现的。因为在默认实现NamespaceHandlerSupport中并未实现init方法,而是提供了registerBeanDefinitionParser、registerBeanDefinitionDecorator、registerBeanDefinitionDecoratorForAttribute三个方法供调用方使用,参考NamespaceHandlerSupport,点我跳转
getHandlerMappings
Map<String, Object> handlerMappings = this.handlerMappings;
if (handlerMappings == null) {
synchronized (this) {
handlerMappings = this.handlerMappings;
if (handlerMappings == null) {
……这里使用了一个DCL单例+懒加载的套路,先获取自己持有的handlerMappings,如果double check还是null,说明没加载过,那么先要加载所有的自定义标签解析器的实现到map里面,如果非null说明以前加载过了,之间获取即可。
if (handlerMappings == null) {
……
try {
Properties mappings =
PropertiesLoaderUtils.loadAllProperties(this.handlerMappingsLocation, this.classLoader);
……
handlerMappings = new ConcurrentHashMap<>(mappings.size());
CollectionUtils.mergePropertiesIntoMap(mappings, handlerMappings);
this.handlerMappings = handlerMappings;
}
……
}到这可以看到是基于成员变量handlerMappingsLocation加载
public DefaultNamespaceHandlerResolver(@Nullable ClassLoader classLoader) {
this(classLoader, DEFAULT_HANDLER_MAPPINGS_LOCATION);
}而根据构造函数又可以看到,真实加载用到的handlerMappingsLocation就是前面步骤取的默认值META-INF/spring.handlers
加载好解析器之后,按照传进来的命名空间,取出对应的解析器,通过反射构造出对应的解析器class,然后做初始化
NamespaceHandlerSupport
init的支持方法
protected final void registerBeanDefinitionParser(String elementName, BeanDefinitionParser parser) {
this.parsers.put(elementName, parser);
}
protected final void registerBeanDefinitionDecorator(String elementName, BeanDefinitionDecorator dec) {
this.decorators.put(elementName, dec);
}
protected final void registerBeanDefinitionDecoratorForAttribute(String attrName, BeanDefinitionDecorator dec) {
this.attributeDecorators.put(attrName, dec);
}虽然NamespaceHandlerSupport没有实现init方法,但是提供了这三个方法给调用方使用
从方法中可以看出来是向三个map成员变量中增加了元素name-parser这样的kv
private final Map<String, BeanDefinitionParser> parsers = new HashMap<>();
private final Map<String, BeanDefinitionDecorator> decorators = new HashMap<>();
private final Map<String, BeanDefinitionDecorator> attributeDecorators = new HashMap<>();这样可以大体上弄清了,NamespaceHandlerSupport主要承担的是内存缓存标签名称对应的parser关系这么一个作用
调用方实现init方法,只需要把自己重写的parser调用上面三个方法初始化好就可以了
parse
public BeanDefinition parse(Element element, ParserContext parserContext) {
BeanDefinitionParser parser = findParserForElement(element, parserContext);
return (parser != null ? parser.parse(element, parserContext) : null);
}可以看出来调用到这里就是在取自定义的parser了,而parser的取方法如下:
private BeanDefinitionParser findParserForElement(Element element, ParserContext parserContext) {
String localName = parserContext.getDelegate().getLocalName(element);
BeanDefinitionParser parser = this.parsers.get(localName);
……
}可以看出来是非常简单的,就是根据elment名称取对应的解析器即可
取出自定义的解析器,就调用到AbstractBeanDefinitionParser#parse ,点我跳转
AbstractBeanDefinitionParser
parse - 公共父类的通用方法
在调用方不重写parse方法的时候,首先会调用到公共父类的parse方法
在这里提供了一套标签解析流程,即解析 - 注册的流程
AbstractBeanDefinition definition = parseInternal(element, parserContext);首先调用parseInternal方法,这就是一个抽象类了,给调用方自行补充
……
BeanDefinitionHolder holder = new BeanDefinitionHolder(definition, id, aliases);
registerBeanDefinition(holder, parserContext.getRegistry());省略上面的一些修饰方法,把解析出来的bd封装成BeanDefinitionHolder,然后调用register方法
protected void registerBeanDefinition(BeanDefinitionHolder definition, BeanDefinitionRegistry registry) {
BeanDefinitionReaderUtils.registerBeanDefinition(definition, registry);
}可以看到这个流程思路和解析默认标签是一样的
if (shouldFireEvents()) {
BeanComponentDefinition componentDefinition = new BeanComponentDefinition(holder);
postProcessComponentDefinition(componentDefinition);
parserContext.registerComponent(componentDefinition);
}最后这里判断如果需要发全局事件,就做一些自定义的后置处理
自定义XML标签的复杂案例
案例1 设计一个person元素,要么上学要么上班,并且一定有一个家属性
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns="http://chymfatfish.cn/schema/person-spring" xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://chymfatfish.cn/schema/person-spring"
elementFormDefault="qualified">
<xsd:element name="person">
<xsd:complexType>
<xsd:sequence>
<xsd:choice minOccurs="0">
<xsd:element ref="school"/>
<xsd:element ref="work"/>
</xsd:choice>
<xsd:element ref="home"/>
</xsd:sequence>
<xsd:attribute name="age" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
<xsd:element name="school">
<xsd:complexType>
<xsd:attribute name="value" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
<xsd:element name="work">
<xsd:complexType>
<xsd:attribute name="value" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
<xsd:element name="home">
<xsd:complexType>
<xsd:attribute name="value" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
</xsd:schema>需求:设计一个person元素,它拥有school、work两个可选子元素,一个home必选子元素,一个age必选属性
设计中的关键点:
targetNamespace要与spring.schemas中定义的key保持一致,定义才有效
xmlns要与targetNamespace保持一致,才能引用到自己定义的element
要对XMLSchema命名空间做一个import,才能使用一些最基础的类型、标签,例如
xsd:string由于
xmlns:xsd="http://www.w3.org/2001/XMLSchema"将XMLSchema命名空间引入时命名为了xsd,,因此该命名空间下的元素最好都以xsd:开头做引用,不然会出现一些意想不到的问题先定义子元素,再定义属性,即
xsd:attribute应该在xsd:element下面理解
<xsd:choice>标签,配合minOccurs和maxOccurs属性,可以在可选列表中任选对应个数,如果不填,属性的默认值为1,即在school和work中选1个,如果maxOccurs=unbounded,即school和work这两个子标签选几个都行
评论区